
XPath є основним елементом стандарту XSLT.
XPath можна використовувати для навігації за елементами та атрибутами у документі XML.
Це означає, що ви можете вибрати будь-який елемент або вміст будь-якого елемента, атрибуту, таблиці або мета-об'єкта у джерелі HTML документа або візуалізованого документа.
Це потужна та захоплююча річ. Працювати з XPath приємно та корисно. На щастя для мене, оскільки я часто працюю з XPath та скреперами.
Сьогодні я хочу навчити вас тому, що я дізнався, і показати вам, як використовувати потужність XPath за допомогою загальнодоступних інструментів SEO.
Подумайте про Інтернет як базу даних
Мені завжди подобалася концепція мислення про Інтернет (джерело даних) як база даних.
Але, звичайно, Інтернет не є великою базою даних. Це колекція сторінок. Багато хто з них, і майже кожна сторінка, що належить окремому веб-сайту, побудованих по-різному. Деякі з них побудовані дуже добре, деякі жахливо. І хоча це все HTML, CSS, JS і т. д. Усі вони побудовані на основі того, що на думку розробника буде найкращим.
Насправді дивно, як браузери можуть зрозуміти все це та показати користувачеві корисну веб-сторінку. Але, коли настав час намагатися зібрати дані, неузгодженість Інтернету може бути вашим найлютішим ворогом. Вилучення даних із веб-сторінок буває надзвичайно складним, оскільки всі вони розмічені трохи інакше.
Тут XPath може допомогти.
Чому це корисно?
Я використовую вирази XPath для створення схем різних сайтів, з яких хочу отримати дані. Деякі з них є разовими завданнями, деякі призначені для дослідження контенту, а деякі потрібні для передачі даних. XPath ефективний тому, що як тільки ви вирішите проблему пошуку найбільш елегантного способу вибору даних в елементі веб-сторінки, він продовжить працювати доти, доки не зміниться її побудова.
Як працює XPath?
Коли ви шукаєте конкретний вираз XPath, найпростіше рішення – скопіювати найкращу версію виразу, який ви можете знайти (зазвичай на Stack). Очевидно, це неминуче, ми всі зайняті, і іноді нам просто необхідно у стислі терміни виправити ситуацію.
Якщо вам потрібний список виразів для шпаргалки XPath, ось деякі з моїх:
|
Елемент |
XPath |
|
заголовок сторінки |
//title |
|
Meta description |
//meta[@name='description']/@content |
|
URL-адреса AMP |
//link[@rel='amphtml']/@href |
|
Канонічний URL |
//link[@rel='canonical']/@href |
|
Robots (Index/Noindex) |
//meta[@name='robots']/@content |
|
H1 |
//h1 |
|
H2 |
//h2 |
|
H3 |
//h3 |
|
Усі посилання у документі |
//@href |
|
Знайти елемент у класі з ім'ям any |
//*[@class='any'] |
Але є щось більше, ніж копіювання виразів XPath.
У XPath є вирази, фільтри (предикати) та функції. Чим краще ви розумієте його можливості, тим вища ймовірність, що ви заощадите час.
Ми почнемо з основ і перейдемо до складніших завдань, які XPath може вирішити пізніше.
Основи: як написати XPath
XPath використовує вирази шляхів для вибору елементів у документі XML (або, звичайно, у HTML-документі!). Отже, основне розуміння шляху, який описує розташування елемента, що вас цікавить - це перша і найважливіша річ, яку ви дізнаєтеся.
Давайте використовуємо цю сторінку на веб-сайті Cheapflights.co.uk.
Подивіться запит XPath, коли я його напишу (ігноруйте пропоновані елементи зараз!).
Інструмент, який я використовую, – Scraper з Інтернет-магазину Chrome. Це простий, але швидкий інструмент для створення та уточнення виразів XPath. Я застосовую його для написання майже всіх моїх виразів XPath, перш ніж переміщати їх у свій інструмент очищення. Ви можете використовувати інструменти Chrome для оцінки та перевірки селекторів XPath і CSS.
Шляхи розташування
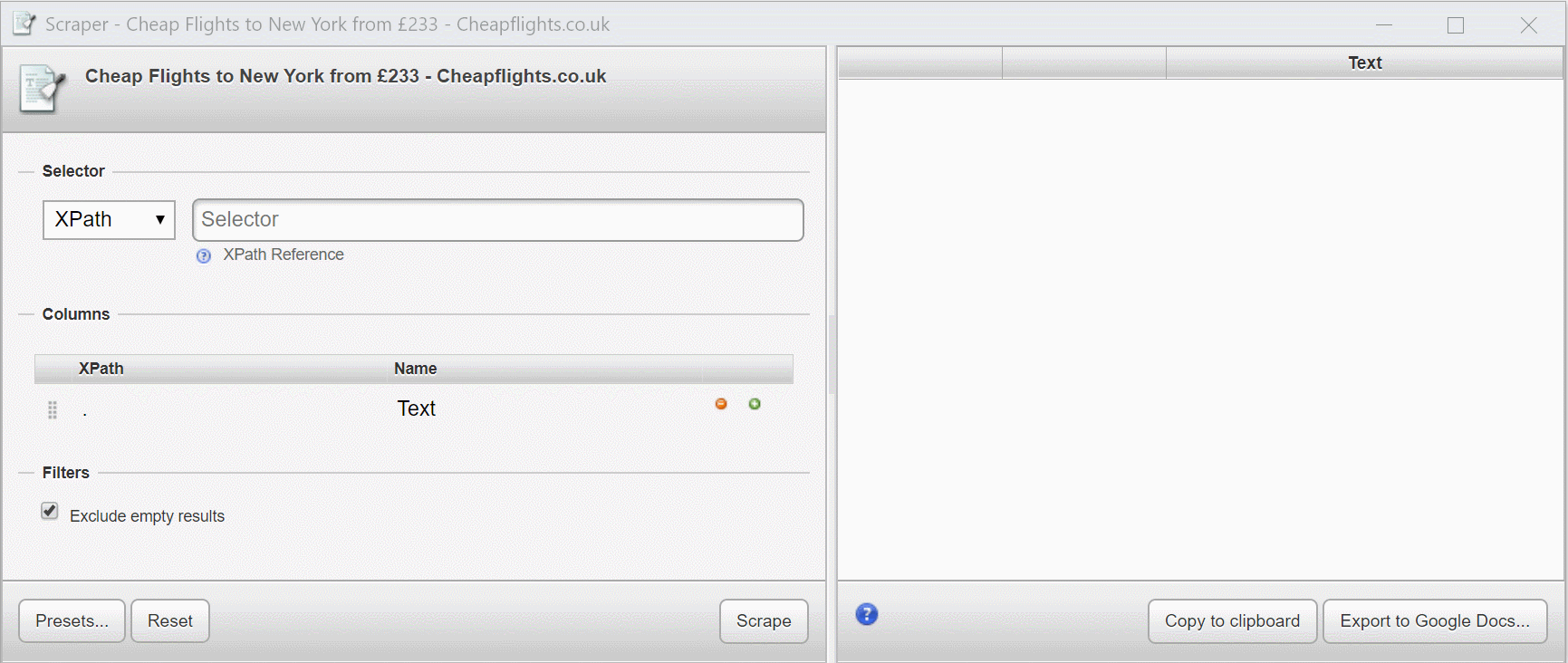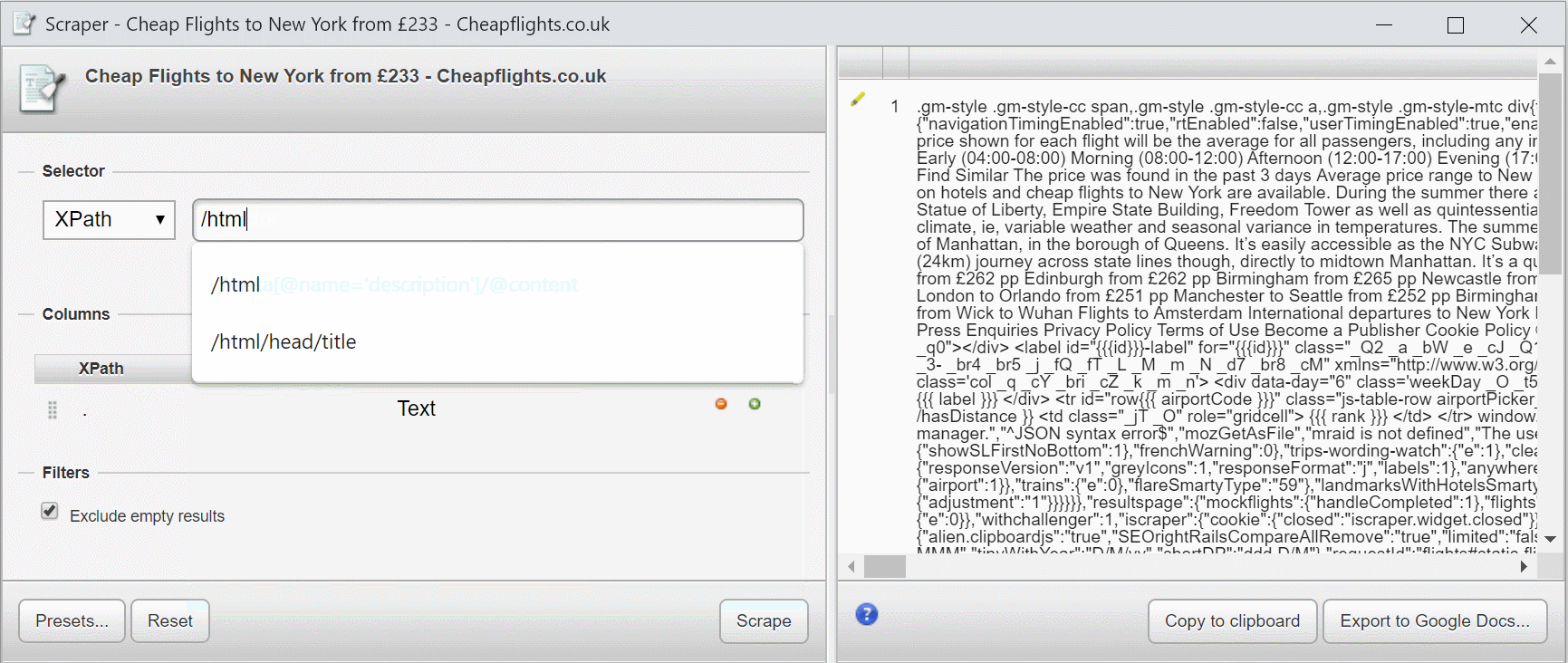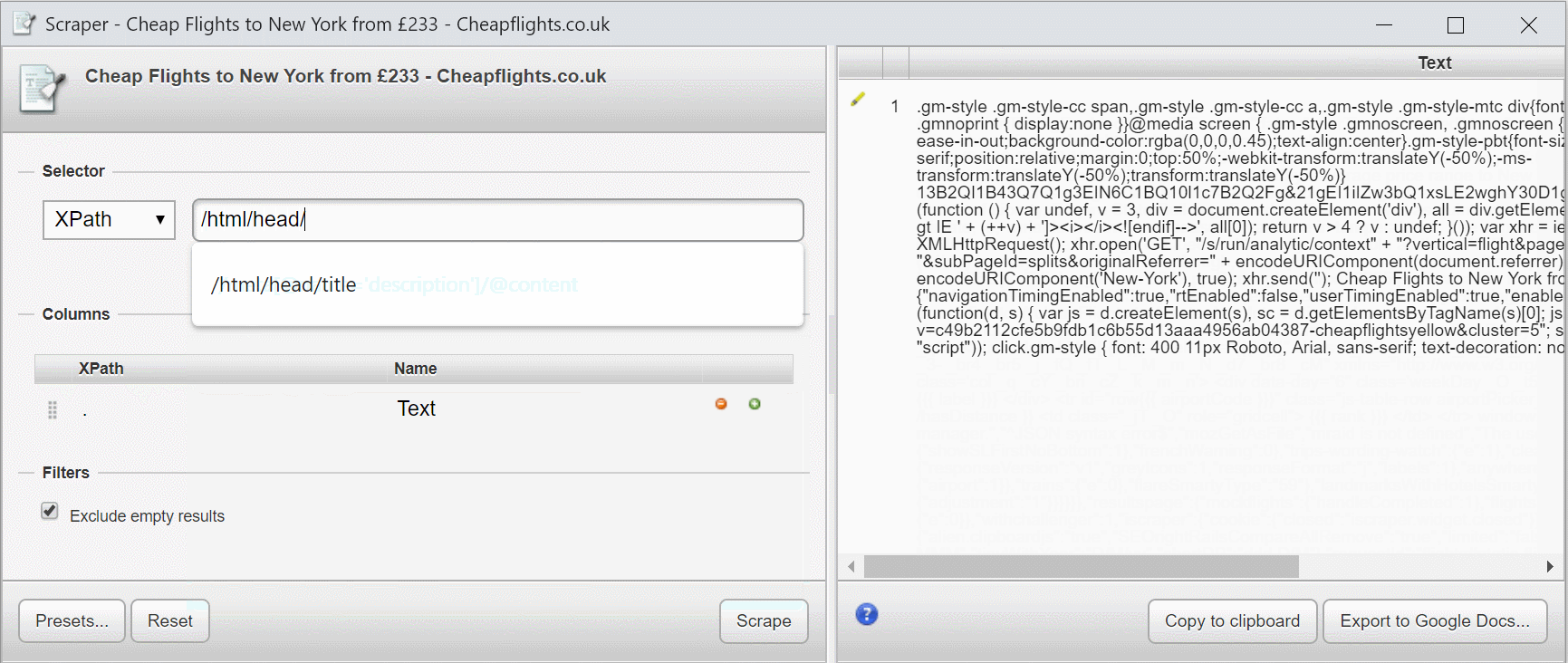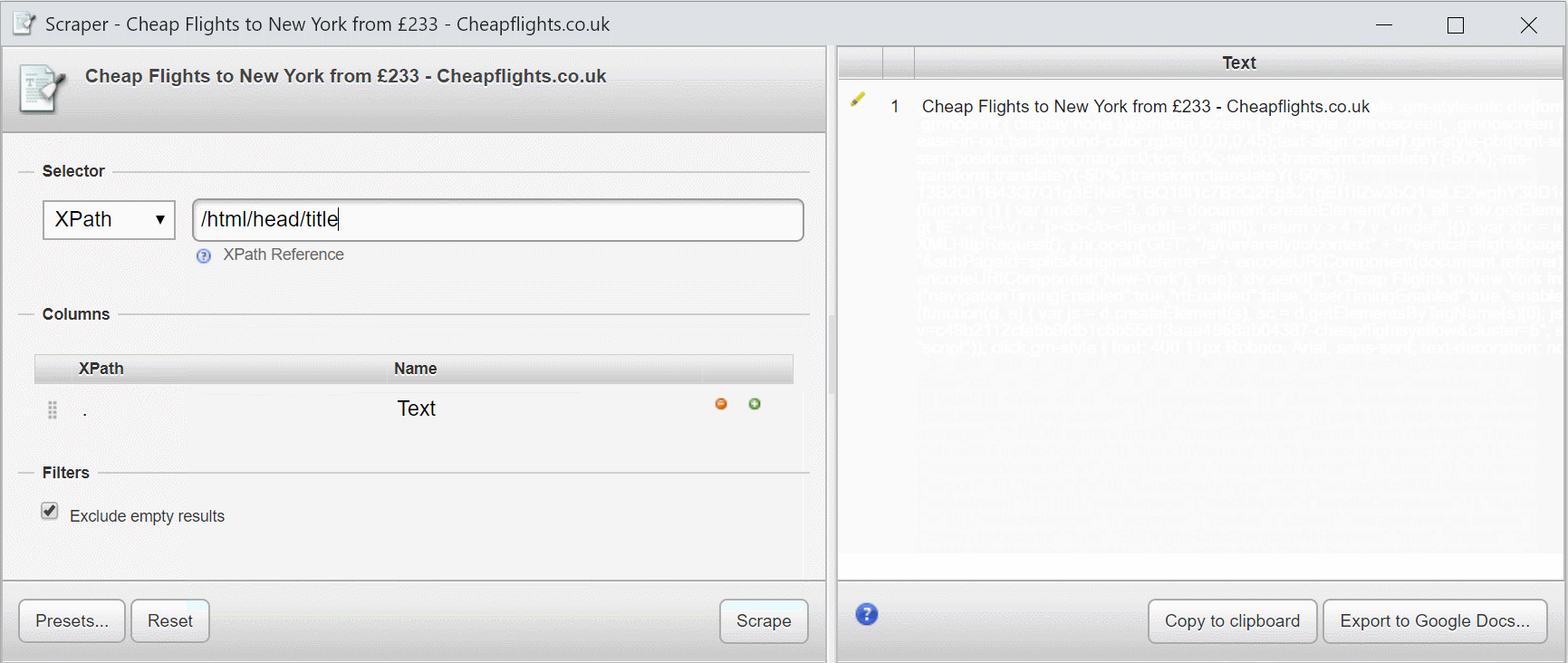
Що в моєму прикладі вище, то це те, що мої XPath-вирази вибираються з кореневого вузла (елемента) з /.
Це по суті вибирає весь документ, як ви побачите в попередньому перегляді.
Якщо я додам /html, нічого не зміниться, оскільки елемент HTML є кореневим вузлом.
Якщо я додам /html/head, вибирається лише вміст елемента head.
Якщо я додам, /html/head/titleя отримаю вміст titleелемента.
Вираз "вузол за вузлом" зазвичай не є тим, як ми пишемо XPath, але корисно пояснити, як це працює.
Таким чином, щоб отримати вміст певного елемента (у нашому випадку title) ми будемо показувати повний шлях, використовуючи скорочений синтаксис: //title.
Саме так:
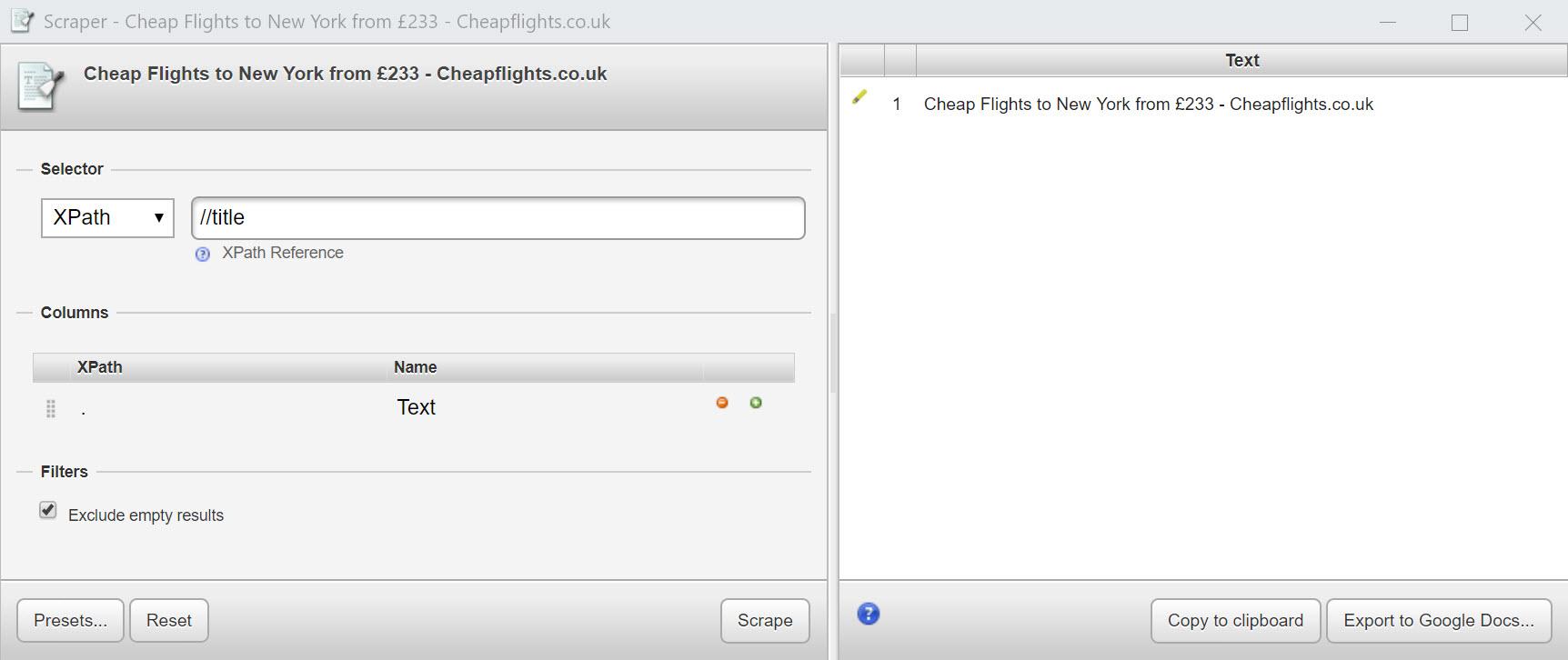
Технічний біт: / / В скороченому синтаксисі короткий descendant-or-self, що означає поточний вузол або будь-який вузол під ним. Ця частина виразу відома як вісь, яка вказує вузол або вузли для вибору на основі їхнього становища в дереві документів (наприклад, вгору, вниз, батьківський, дочірній і т. д.).
Вилучення атрибутів
Що робити, якщо ви хочете отримати атрибут href з усіх елементів на сторінці?
Використання: //a/@href
//@href надасть вам всі атрибути href з будь-якого рядка джерела сторінки, включаючи посилання на css-файли, JavaScript і т.д.
Ви можете досягти того ж результату //*/@href.
Бажаєте отримати комплексний аналіз вашого сайту?
Предикати
Предикат дуже схожий на створення інструкції if / then всередині виразу XPath. Якщо результат TRUE, тоді буде вибрано елемент на вашій сторінці. Якщо результат предикату FALSE – його буде виключено.
Розглянемо цей вираз:
//*[@class='any']
Який вибере будь-який елемент із класом CSS any.
Вилучення ціни зі сторінки продукту
Давайте розглянемо щось подібне практично з цією сторінкою продукту для лампи Anglepoise . Я виділив ціну на фактичній сторінці та відповідний код, знайдений через Inspect у Chrome Developer Tools.

Щоб отримати ціну, ми фактично маємо кілька корисних точок даних у розмітці.
Або, контейнер P з атрибутом класу CSS, class="price price--large" або структуровані дані схеми продукту .
Я хотів би використовувати посилання Schema, але для повноти давайте використовувати обидва приклади:
//p[@class='price price--large'] який забезпечить:
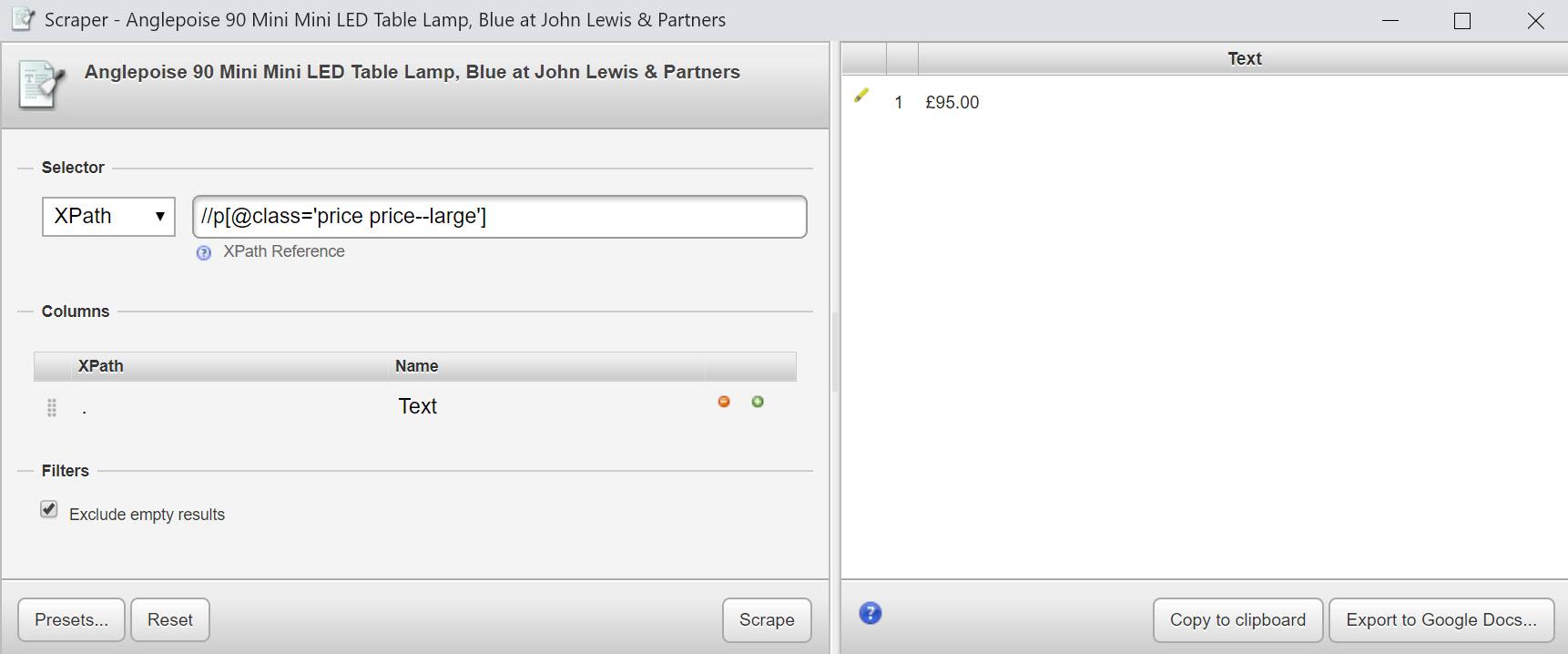
Хоча ви можете бачити, що у джерелі HTML є багато вільного місця за цією ціною, тому було б непогано обернути все це на функцію normalize-space:
//p[normalize-space(@class) ='price price--large']
Ми також могли б піти іншим шляхом, використовуючи структуровані дані на сторінці. Припускаючи, що розмітка схеми для продуктів не зміниться в найближчому майбутньому, внісши зміни в структуру HTML та імена класів CSS їхнього сайту.
Спробуйте це: //meta[@itemprop='price']/@content
або ж
//*[@itemprop='price']/@content
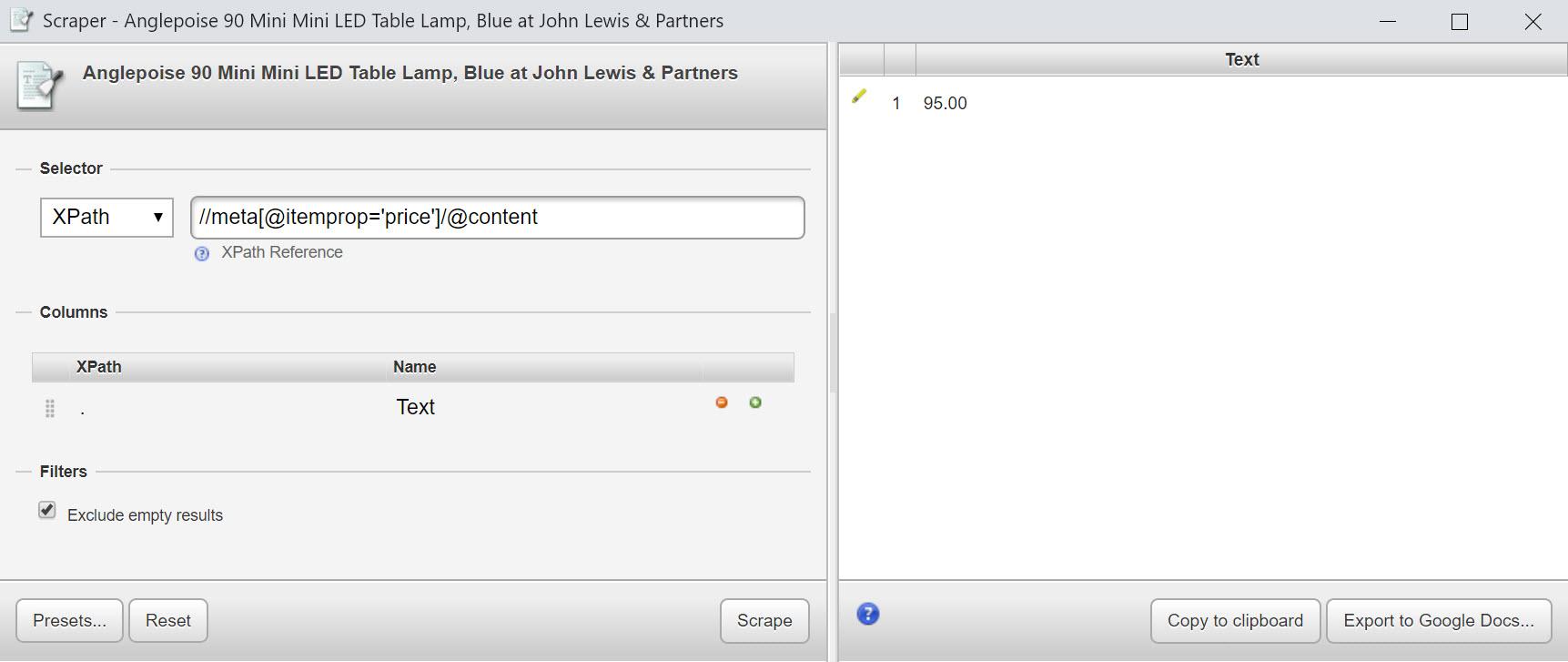
Використовуючи наш вираз вище, ми можемо отримати багато цікавої інформації з структурованих даних на цій сторінці продукту, у тому числі:
|
Елемент |
XPath |
|
Ціна |
//meta[@itemprop='price']/@content |
|
Образ |
//meta[@itemprop='image']/@content |
|
Назва |
//h1[@itemprop='name'] |
|
Код товарів |
//header[@itemprop='productId']/@content |
|
Стан запитів |
//meta[@itemprop='availability']/@content |
Читайте також
Як вивести поточну структуру сайту
Вилучення даних із таблиць
Я зіткнувся з цікавою проблемою, коли важливі елементи даних, такі як продукт SKU і вага, були розміщені в таблиці «Технічні деталі» наступним чином:
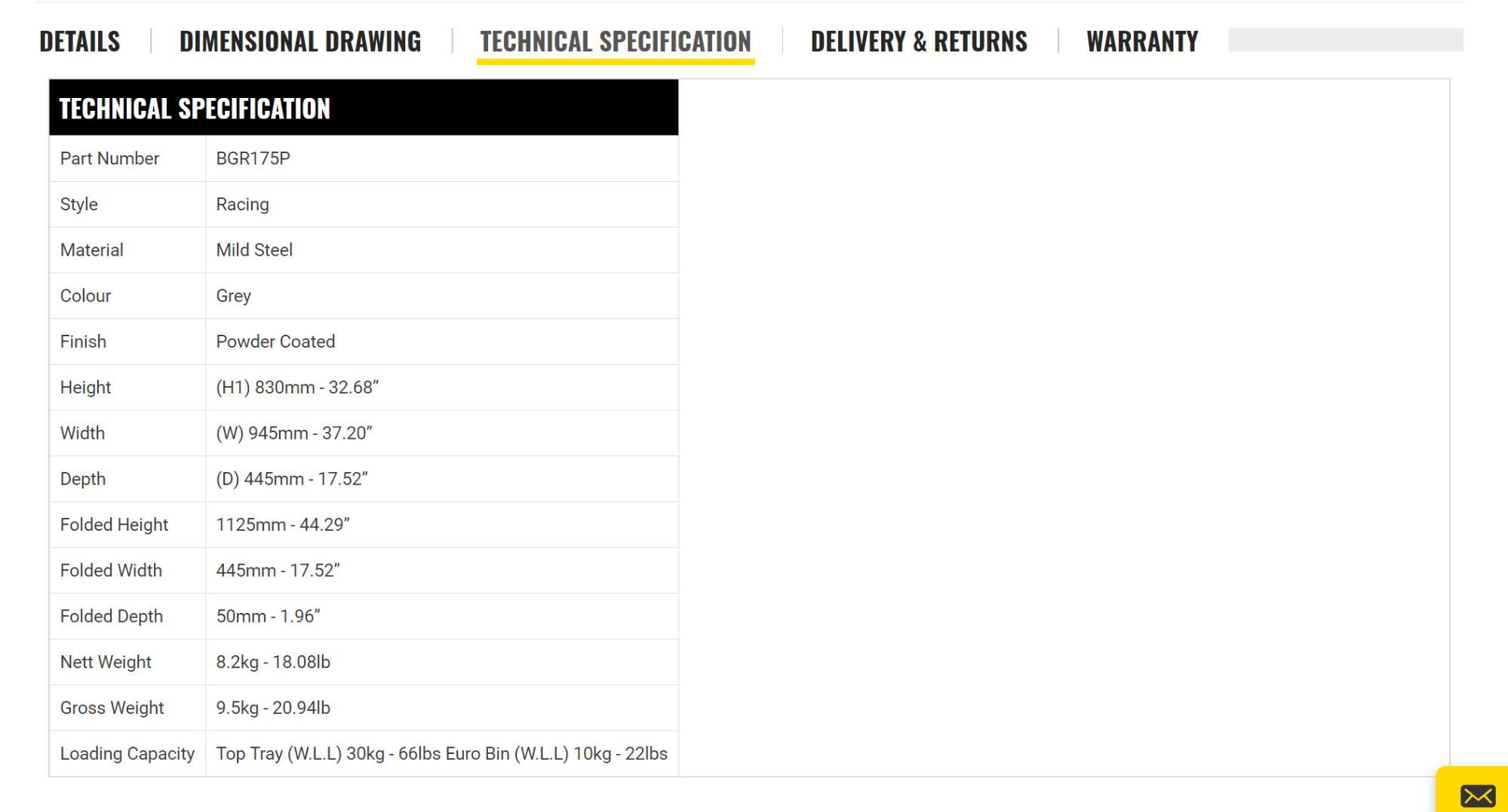
Щоб отримати SKU, я вибрав комірку таблиці, що містить текст «BG», використовуючи text() тест вузла :
//td[contains(text(),'BG')]
З вагою, проте, проблема була дещо іншою, оскільки числа в осередку цінності завжди різні! Рішення виглядає так:
//td[contains(text(),'Weight')]/following-sibling::td
Де following-sibling вибирає значення, що міститься в наступному td по осі.
Це вирішення проблеми для конкретної ніші, але якщо вам коли-небудь доведеться витягувати дані з таблиць, які різняться за розміром і форматом, це може допомогти!
Функції XPath
Функції XPath, які я найчастіше використовую:
- Count()
- Contains()
- Starts-with()
- Normalize-space()
Використання Count
Зі всіх функцій, які мені подобаються, ця повною мірою демонструє, наскільки потужним може бути XPath. Крім того, велике спасибі команді Screaming Frog за показ парсера XPath, який справді працює.
Розглянемо цю сторінку ціни на рейс .
У ній перераховані деякі пропозиції щодо авіарейсів (як і слід очікувати, але скільки?). Кожна угода відзначена атрибутом класу CSS "resultPrice".
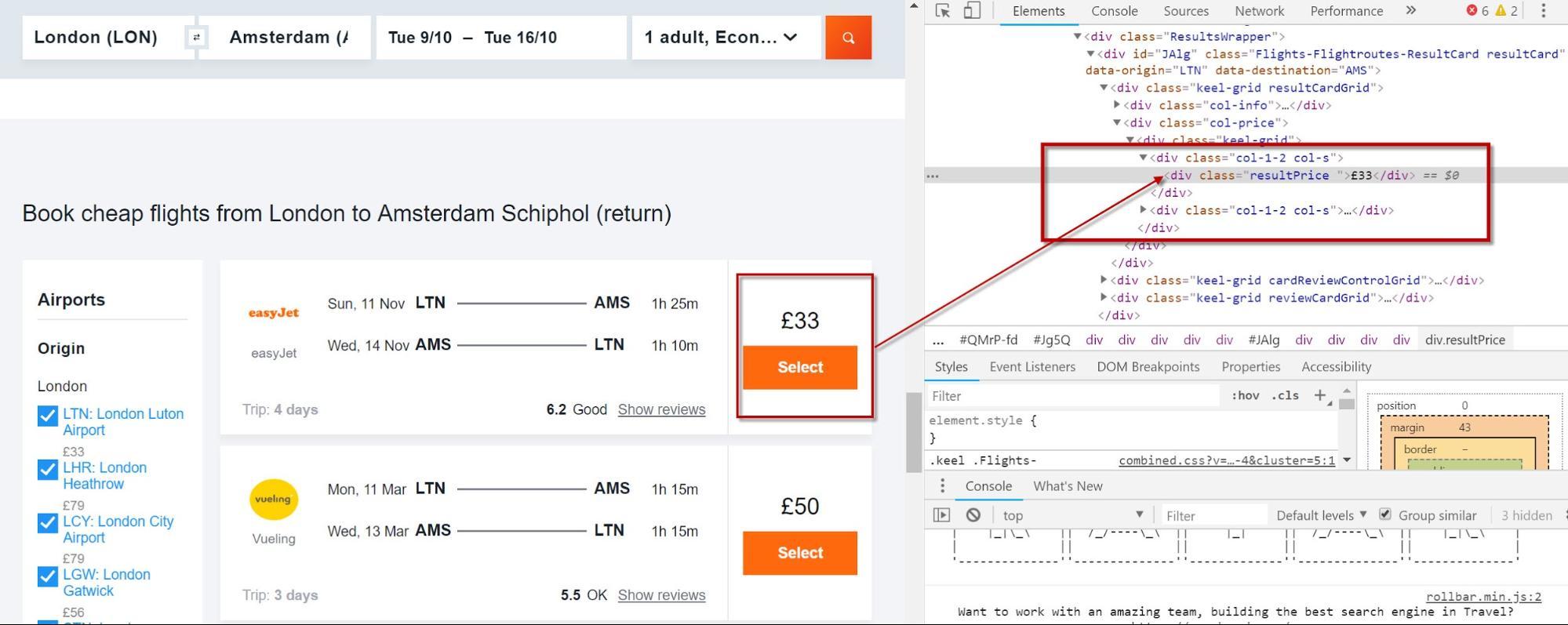
Спробуйте обернути вираз XPath функцією Count () та додати інструмент Custom Extraction від Screaming Frog:
count(//div[@class='resultPrice'])
Обов'язково виберіть «Значення функції» як бажаний результат:

Результат підрахунку відображатиметься у стовпці у звичайному місці:

Невелика кількість угод, перерахованих на сторінці, може значно змінити конверсію. І не в позитивному ключі! Раніше було дуже складно швидко оцінити сторінки зі слабким листинговим контентом (якщо, звичайно у вас не було часу для запиту бази даних).
Завдяки Count(), цю проблему вирішено. Для рітейлерів визначення слабких сторінок категорії без гідного рівня охоплення продукту не складе великої праці.
Використання Contains та Starts-with
Contains і starts-with є корисними функціями пошуку, які я міг би використовувати, щоб зібрати всі атрибути, схожі тим, що вони починаються з тих самих символів, але закінчуються інакше, просто містять символи, які я шукаю.
Щось у цьому напрямі може спрацювати для вас:
//*[contains(@class, 'service')]
Або ж
//*[starts-with(@class, 'service')]
Видаліть пробіли за допомогою Normalize-Space
Нарешті, ми розглянемо normalize-spaceраніше у статті - корисну функцію для того, щоб вирізати порожній простір на початку і в кінці рядка тексту, замінюючи послідовності символів пробілу на один простір.
Як зібрати дані
Ми говорили про розширення Scraper для Chrome, яке має безліч переваг, але не підходить для серйозного збору даних. Які інші варіанти нам доступні?
Scrapinghub
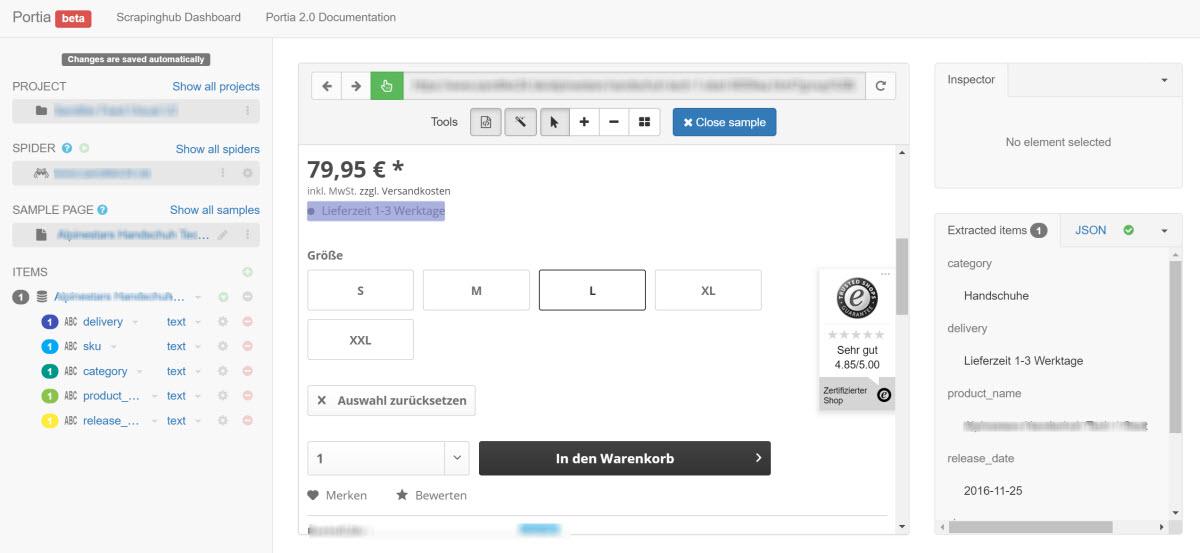
Scrapinghub - це потужний, масштабований та недорогий інструмент для очищення. Scrapy Cloud являє собою середовище, орієнтоване на розробника, сконфігуроване спеціально для очищення. Тут також є візуальний інтерфейс під назвою Portia, який може приймати візуальні точки та кліки введення. Він також приймає селектори XPath і CSS Selectors.
Інструменти SEO для Excel
Багато фахівців, з якими я говорив, визнають, що не чули про SEO Tools for Excel . Проте, на мою думку, остання версія досить функціональна і з нею варто ознайомитися ближче. Функція XpathOnURL() може отримувати дані з 10000 URL. Багатопотокові функції плагіна також дозволяють продовжити роботу в Excel на іншій вкладці, така різниця між старими та новими версіями!
Screaming Frog
Як я продемонстрував вище, користувальницька функція вилучення в Screaming Frog є неймовірно потужною. Цей інструмент не потребує жодного значення. Все, що я скажу, це те, що він, як правило, мій перший порт-виклик, коли я створюю прототипи нових ідей, де необхідний XPath.
Звичайний користувальницький екстрактор для мене може виглядати так:



Залишіть ваші контактні дані.
Будемо раді обговорити ваш проект!