
XPath является основным элементом стандарта XSLT.
XPath можно использовать для навигации по элементам и атрибутам в документе XML.
Это означает, что вы можете выбрать любой элемент или содержимое любого элемента, атрибута, таблицы или мета-объекта в источнике HTML документа или визуализированного документа.
Это мощная и захватывающая вещь. Работать с XPath приятно и полезно. К счастью для меня, поскольку я часто работаю с XPath и скреперами.
Сегодня я хочу научить вас тому, что я узнал, и показать вам, как использовать мощь XPath, с помощью общедоступных инструментов SEO.
Подумайте об Интернете как базе данных
Мне всегда нравилась концепция мышления об Интернете (источнике данных), как база данных.
Но, конечно, Интернет не является большой базой данных. Это коллекция страниц. Многие из них, и почти каждая страница, принадлежащая отдельному веб-сайту, построенных по-разному. Некоторые из них построены очень хорошо, некоторые – ужасно. И, хотя это все HTML, CSS, JS и т. д. Все они построены на основе того, что по мнению разработчика будет наилучшим.
На самом деле удивительно, как браузеры могут понять все это и показать пользователю полезную веб-страницу. Но, когда приходит время пытаться собрать данные, несогласованность Интернета может быть вашим злейшим врагом. Извлечение данных с веб-страниц бывает чрезвычайно сложным, так как все они размечены несколько иначе.
Здесь XPath может помочь.
Почему это полезно?
Я использую выражения XPath для создания схем разных сайтов, из которых хочу извлечь данные. Некоторые из них являются разовыми задачами, некоторые предназначены для и исследования контента, а некоторые нужны для передачи данных. XPath эффективен потому, что, как только вы решите проблему поиска наиболее элегантного способа выбора данных в элементе веб-страницы, он продолжит работать до тех пор, пока не изменится ее построение.
Как работает XPath?
Когда вы ищете конкретное выражение XPath, самое простое решение – скопировать лучшую версию выражения, которое вы можете найти (обычно на Stack). Очевидно, это неизбежно, мы все заняты, и иногда нам просто необходимо в краткие сроки исправить ситуацию.
Если вам нужен список выражений для шпаргалки XPath, вот некоторые из моих:
|
Элемент |
XPath |
|
Заголовок страницы |
//title |
|
Meta description |
//meta[@name='description']/@content |
|
URL-адрес AMP |
//link[@rel='amphtml']/@href |
|
Канонический URL |
//link[@rel='canonical']/@href |
|
Robots (Index/Noindex) |
//meta[@name='robots']/@content |
|
H1 |
//h1 |
|
H2 |
//h2 |
|
H3 |
//h3 |
|
Все ссылки в документе |
//@href |
|
Найти элемент в классе с именем any |
//*[@class='any'] |
Но есть нечто большее, чем копирование выражений XPath.
В XPath есть выражения, фильтры (предикаты) и функции. Чем лучше вы понимаете его возможности, тем выше вероятность, что вы сэкономите время.
Мы начнем с основ и перейдем к более сложным задачам, которые XPath может решить позже.
Основы: как написать XPath
XPath использует выражения путей для выбора элементов в документе XML (или, конечно же, в HTML-документе!). Итак, основное понимание пути, который описывает расположение интересующего вас элемента – это первая и самая важная вещь, которую вы узнаете.
Давайте используем эту страницу на сайте Cheapflights.co.uk.
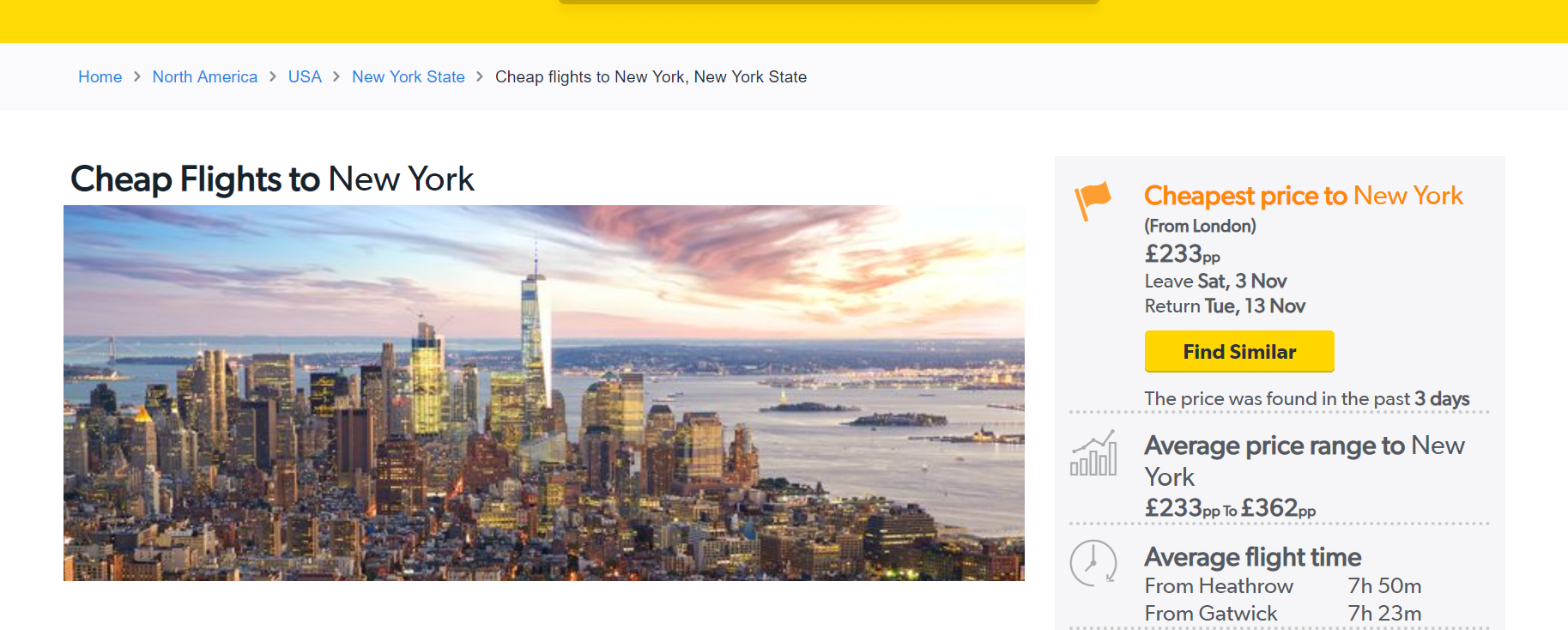
Взгляните на запрос XPath, когда я его напишу (игнорируйте предлагаемые элементы сейчас!).
Инструмент, который я использую – Scraper из Интернет-магазина Chrome. Это простой, но быстрый инструмент для создания и уточнения выражений XPath. Я применяю его для написания почти всех моих выражений XPath, прежде чем перемещать их в свой инструмент очистки. Вы можете использовать инструменты разработчика Chrome для оценки и проверки селекторов XPath и CSS.
Пути расположения
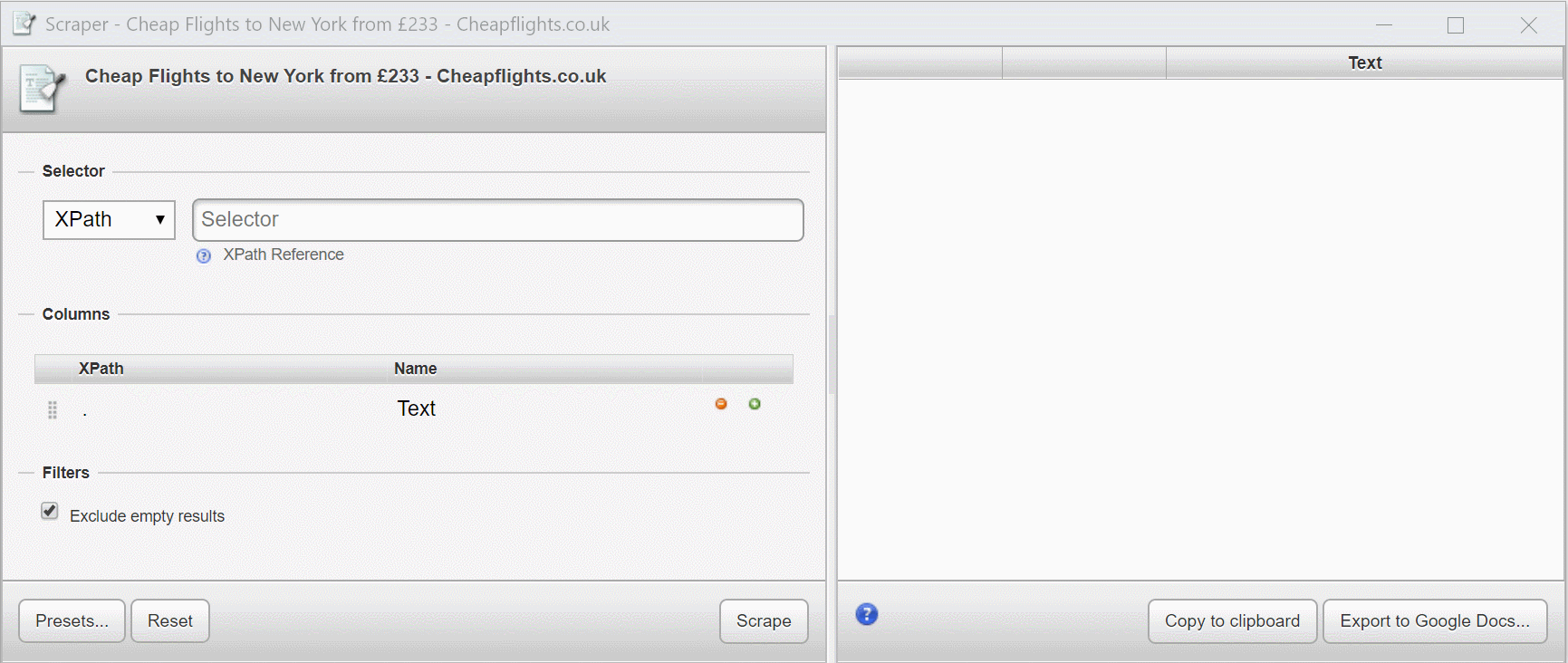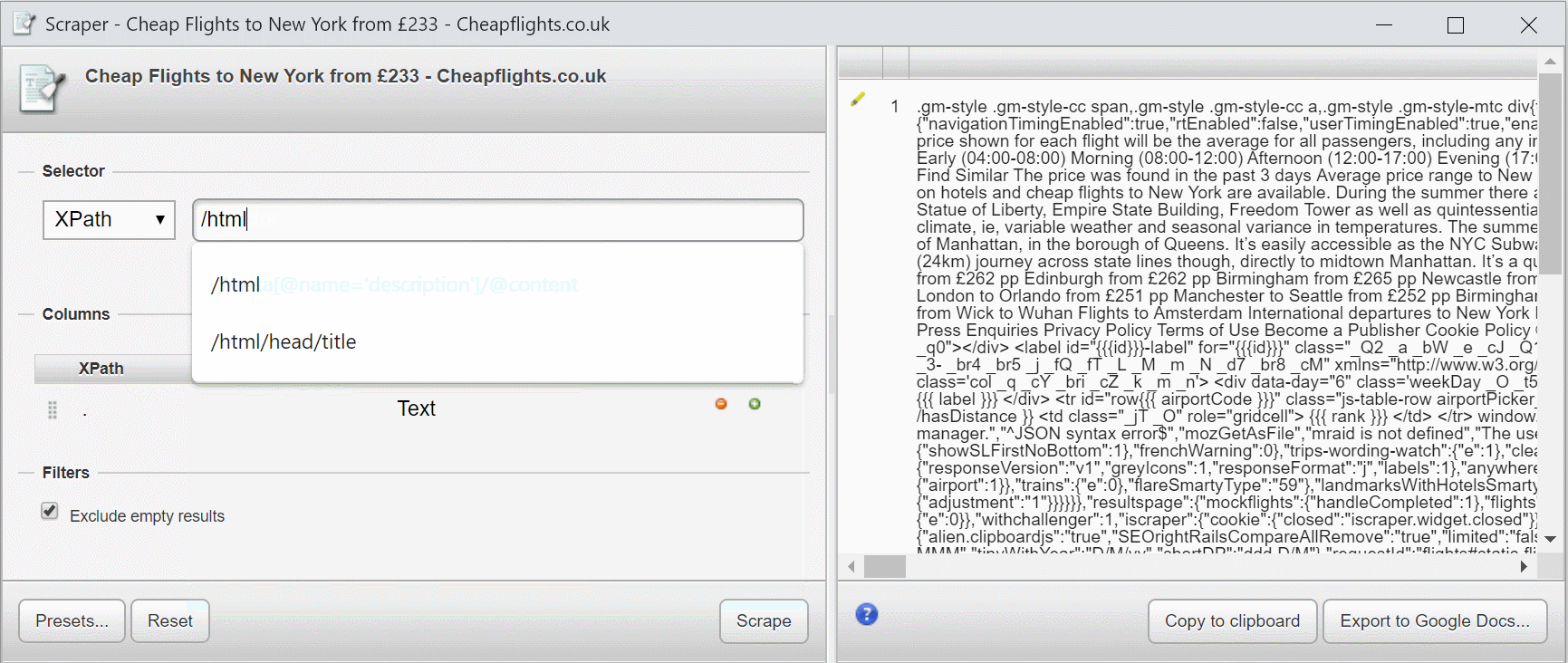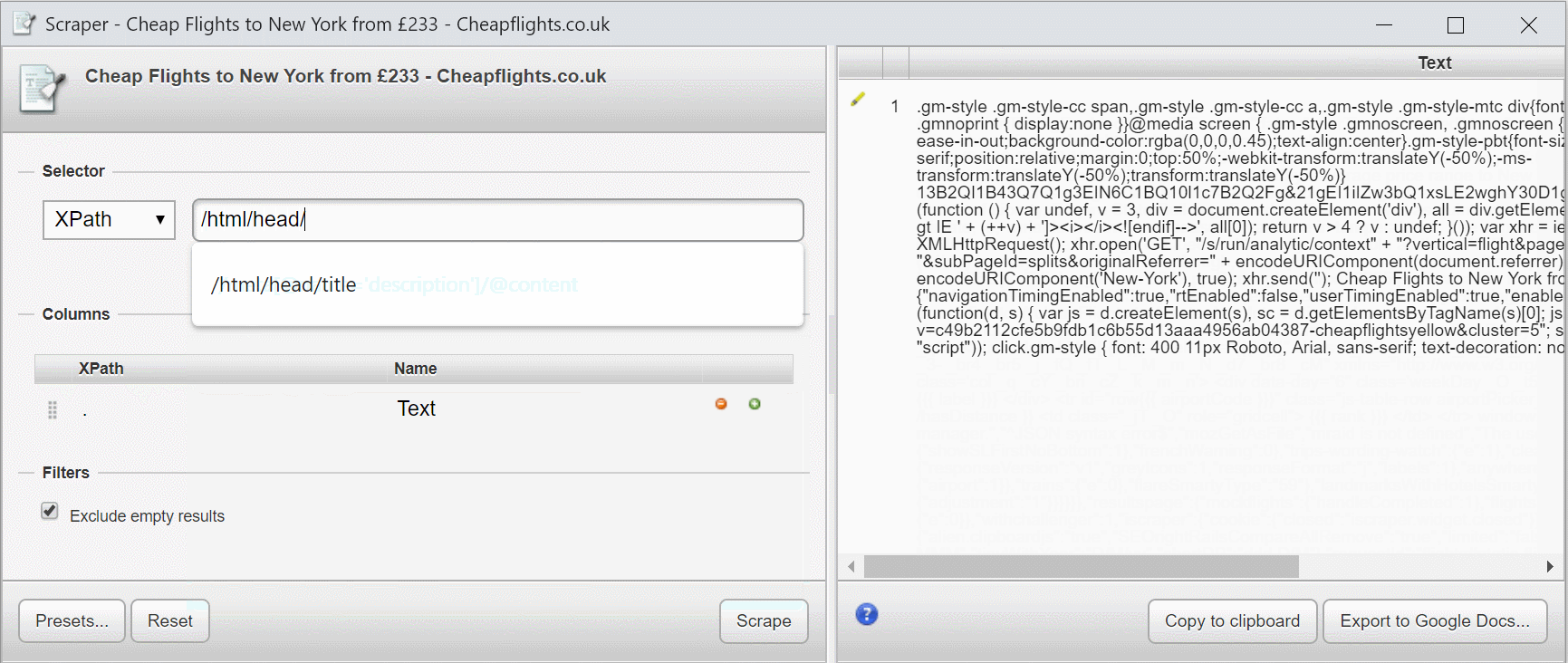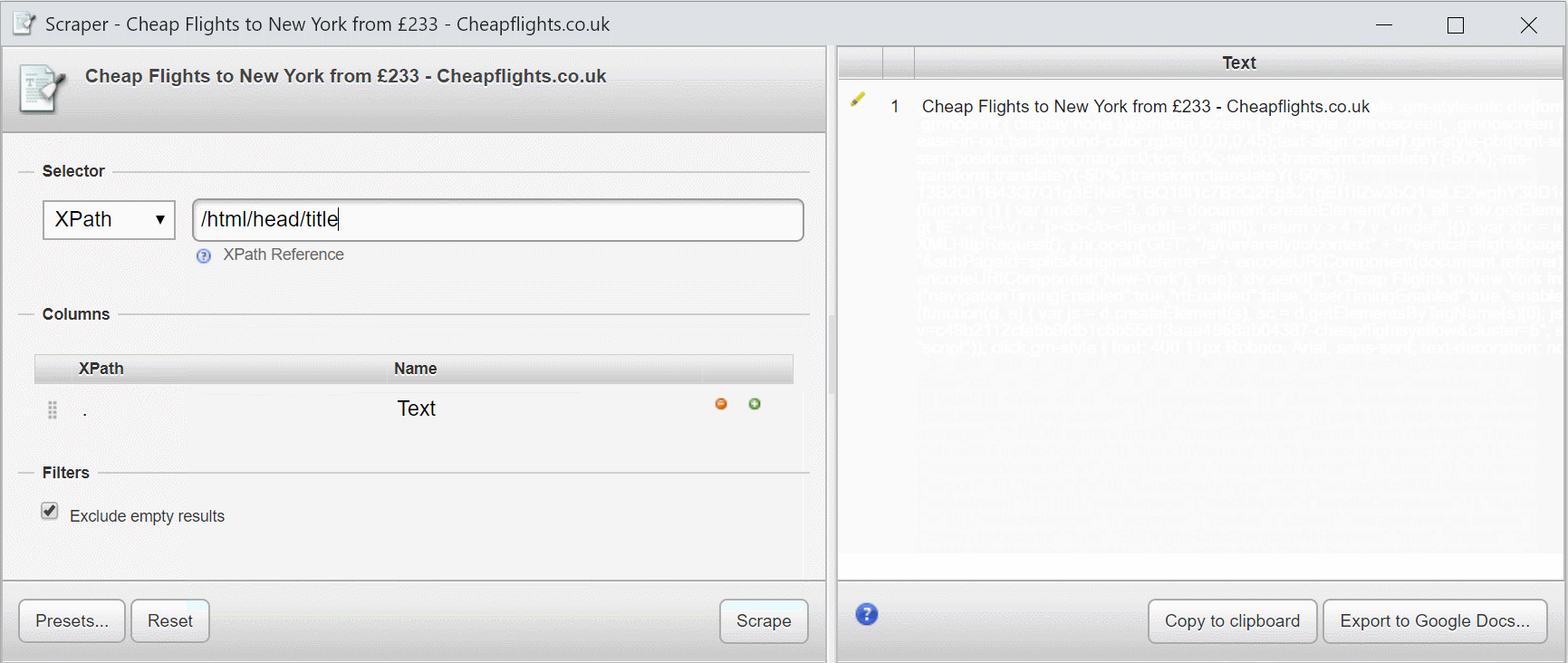
Что в моем примере выше, так это то, что мои XPath-выражения выбираются из корневого узла (элемента) с /.
Это, по существу, выбирает весь документ, как вы увидите в предварительном просмотре.
Если я добавлю /html, ничего не изменится, так как элемент html является корневым узлом.
Если я добавлю /html/head, выбирается только содержимое элемента head.
Если я добавлю, /html/head/titleя получу содержимое titleэлемента.
Выражение «узел за узлом» обычно не является тем, как мы пишем XPath, но полезно объяснить, как это работает.
Таким образом, чтобы извлечь содержимое определенного элемента (в нашем случае title) мы будем показывать полный путь, используя сокращенный синтаксис: //title.
Именно так:
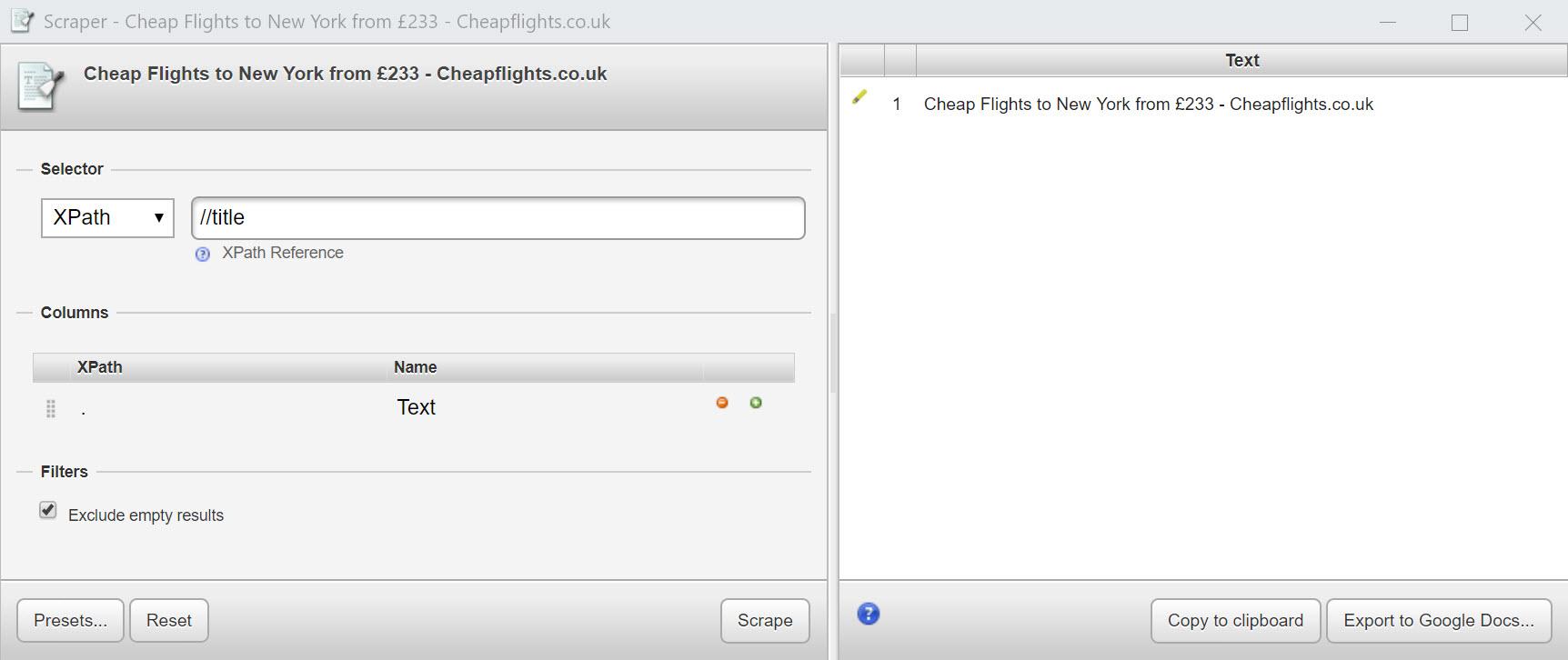
Технический бит: //в сокращенном синтаксисе короткий descendant-or-self, что означает текущий узел или любой узел под ним. Эта часть выражения известна как ось, которая указывает узел или узлы для выбора на основе их положения в дереве документов (например, вверх, вниз, родительский, дочерний и т. Д.).
Извлечение атрибутов
Что делать, если вы хотите извлечь атрибут href из всех элементов на странице?
Использование: //a/@href
//@href предоставит вам все атрибуты href из любой строки источника страницы, включая ссылки на css-файлы, JavaScript и т. д.
Вы можете добиться того же результата //*/@href.
Хотите получить комплексный анализ вашего сайта?
Предикаты
Предикат очень похож на создание инструкции if / then внутри вашего выражения XPath. Если результат TRUE, тогда будет выбран элемент на вашей странице. Если результат предиката FALSE – он будет исключен.
Рассмотрим это выражение:
//*[@class='any']
Который выберет любой элемент с классом CSS «any».
Извлечение цены со страницы продукта
Давайте расмотрим что-то подобное на практике с этой страницей продукта для лампы Anglepoise . Я выделил цену на фактической странице и соответствующий код, найденный через Inspect в Chrome Developer Tools.

Чтобы получить цену, у нас фактически есть несколько полезных точек данных в разметке.
Либо, контейнер P с атрибутом класса CSS, class="price price--large" либо структурированные данные схемы продукта.
Я бы предпочел использовать ссылку Schema, но для полноты давайте использовать оба примера:
//p[@class='price price--large'] который обеспечит:
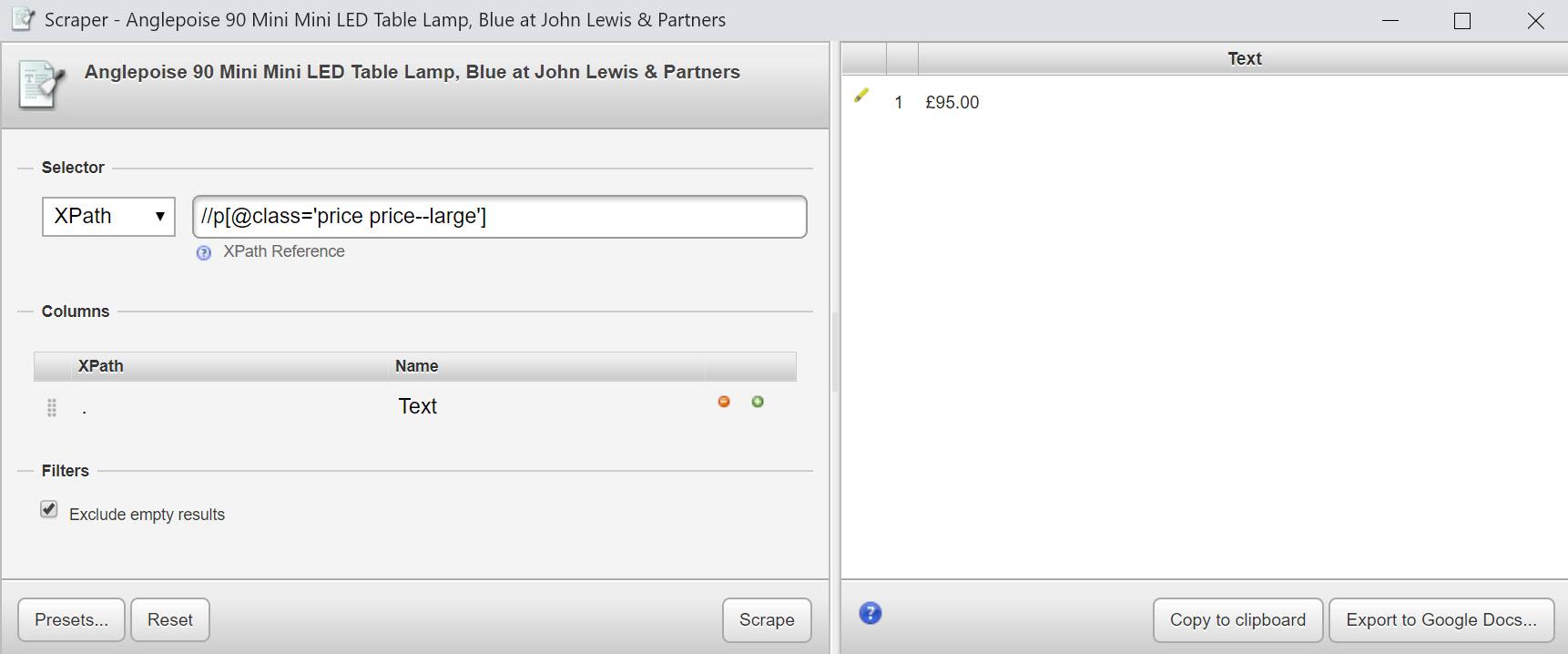
Хотя вы можете видеть, что в источнике HTML есть много свободного места по этой цене, поэтому было бы неплохо обернуть все это в функцию normalize-space:
//p[normalize-space(@class) ='price price--large']
Мы также могли бы пойти другим путем, используя структурированные данные на странице. Предполагая, что разметка схемы для продуктов не изменится в ближайшем будущем, внеся какие-либо изменения в структуру HTML и имена классов CSS их сайта.
Попробуйте это: //meta[@itemprop='price']/@content
или же
//*[@itemprop='price']/@content
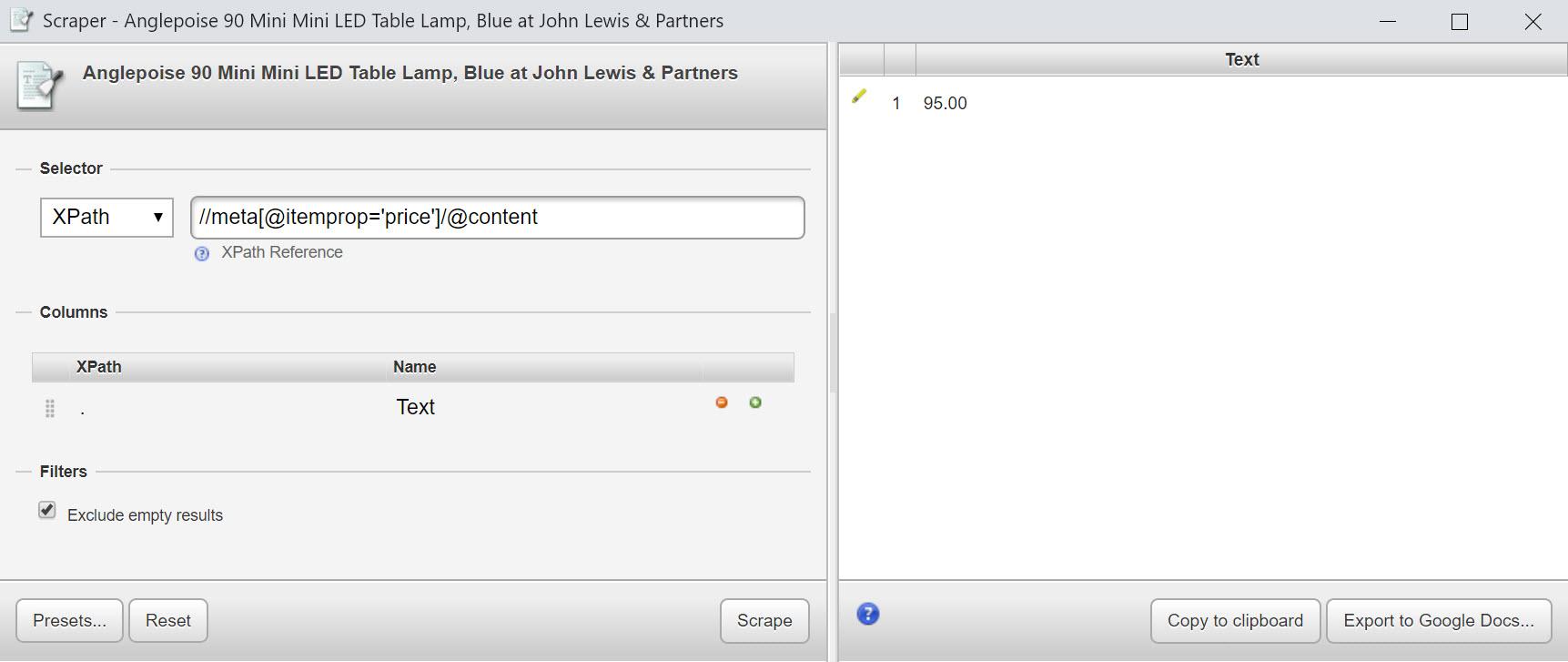
Используя наше выражение выше, мы можем извлечь много интересной информации из структурированных данных на этой странице продукта, в том числе:
|
Элемент |
XPath |
|
Цена |
//meta[@itemprop='price']/@content |
|
Образ |
//meta[@itemprop='image']/@content |
|
Название |
//h1[@itemprop='name'] |
|
Код товаров |
//header[@itemprop='productId']/@content |
|
Состояние запросов |
//meta[@itemprop='availability']/@content |
Читайте также
Как вывести текущую структуру сайта
Извлечение данных из таблиц
Я столкнулся с интересной проблемой, когда важные элементы данных, такие как SKU продукта и вес, были размещены в таблице «Технические детали» следующим образом:
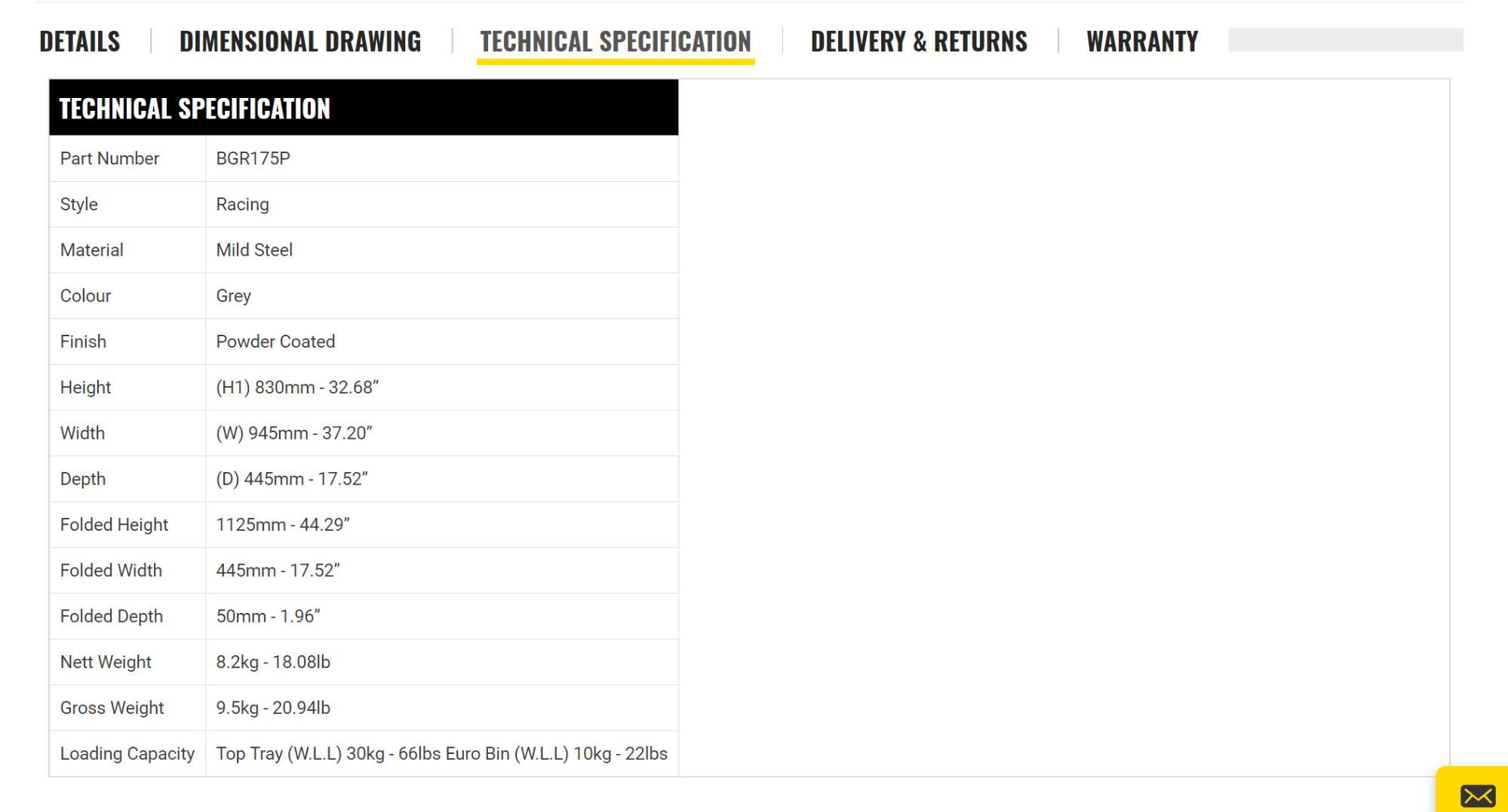
Чтобы извлечь SKU, я выбрал ячейку таблицы, содержащую текст «BG», используя text() тест узла:
//td[contains(text(),'BG')]
С весом, однако, проблема была несколько иной, поскольку числа в ячейке ценности всегда разные! Решение выглядит так:
//td[contains(text(),'Weight')]/following-sibling::td
Где following-siblingвыбирает значение, содержащееся в следующем td по оси.
Это решение проблемы для конкретной ниши, но, если вам когда-либо придется извлекать данные из таблиц, которые различаются по размеру и формату, это может помочь!
Функции XPath
Функции XPath, которые я чаще всего использую:
- Count()
- Contains()
- Starts-with()
- Normalize-space()
Использование Count
Из всех функций, которые мне нравятся, эта в полной мере демонстрирует, насколько мощным может быть XPath. Кроме того, огромное спасибо команде Screaming Frog за показ парсера XPath, который действительно работает.
Рассмотрим эту страницу цены на рейс.
В ней перечислены некоторые предложения по авиарейсам (как и следовало ожидать, но сколько?). Каждая сделка отмечена атрибутом класса CSS «resultPrice».
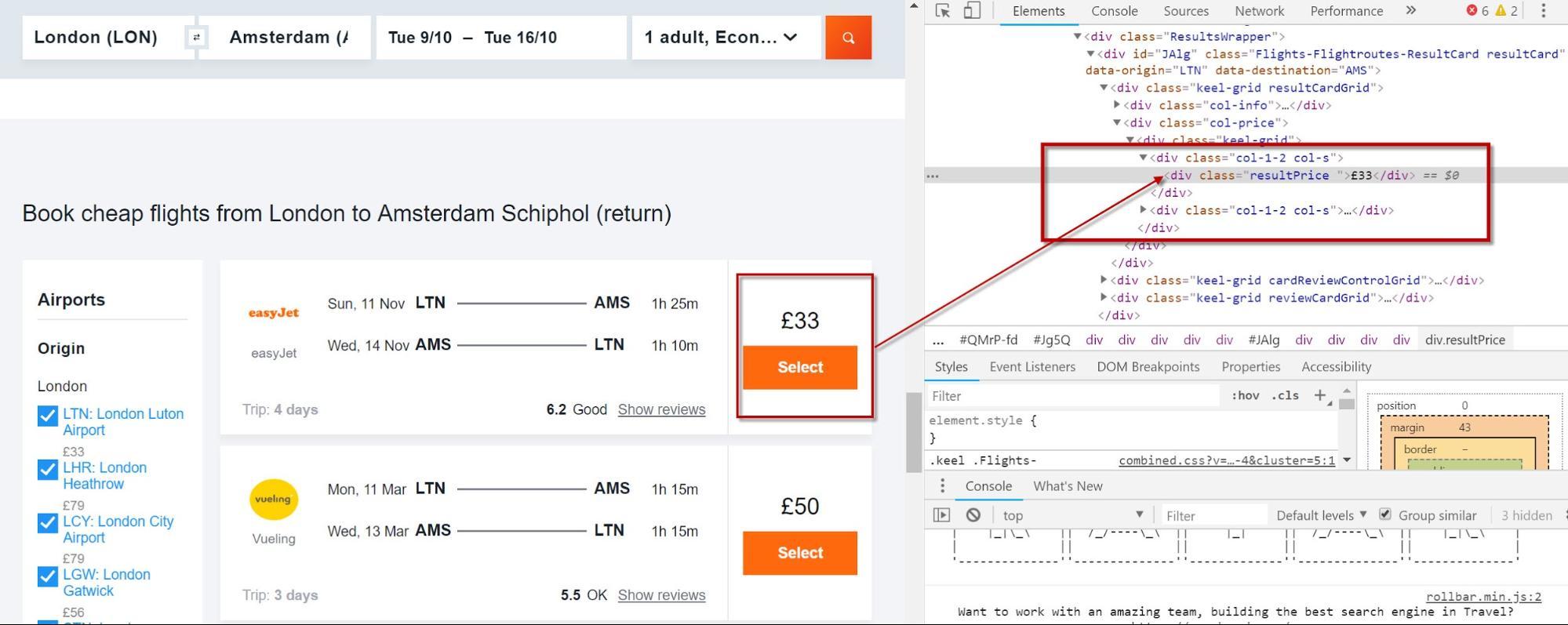
Попробуйте обернуть выражение XPath функцией Count () и добавить инструмент Custom Extraction от Screaming Frog:
count(//div[@class='resultPrice'])
Обязательно выберите «Значение функции» в качестве желаемого результата:

Результат подсчета будет отображаться в столбце в обычном месте:

Малое количество сделок, перечисленных на странице, может значительно изменить конверсию. И не в позитивном ключе! Раньше было ужасно сложно быстро оценить страницы со слабым листинговым контентом (если, конечно у вас не было времени для запроса базы данных).
Благодаря Count (), эта проблема решена. Для ритейлеров, определение слабых страниц категории без достойного уровня охвата продукта, не составит большого труда.
Использование Contains и Starts-with
Contains и starts-with являются полезными функциями поиска, которые я мог бы использовать, чтобы собрать все атрибуты, похожие тем, что они начинаются с одних и тех же символов, но заканчиваются иначе, просто содержащие символы, которые я ищу.
Что-то в этом направлении может сработать для вас:
//*[contains(@class, 'service')]
Или же
//*[starts-with(@class, 'service')]
Удалите пробелы с помощью Normalize-Space
Наконец, мы рассмотрим normalize-spaceранее в статье – полезную функцию для того, чтобы вырезать пустое пространство в начале и в конце строки текста, заменяя последовательности символов пробела на одно пространство.
Как собрать данные
Мы говорили о расширении Scraper для Chrome, которое обладает множеством преимуществ, но не подходит для серьезного сбора данных. Итак, какие другие варианты нам доступны?
Scrapinghub
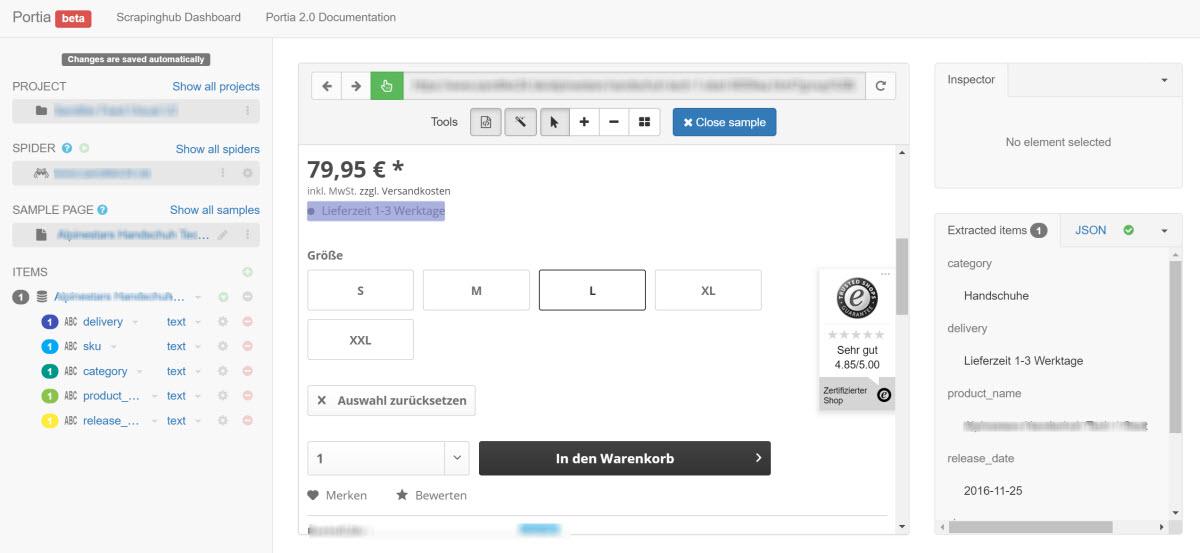
Scrapinghub - это мощный, масштабируемый и недорогой инструмент для очистки. Scrapy Cloud представляет собой среду, ориентированную на разработчика, сконфигурированная специально для очистки. Здесь также присутствует визуальный интерфейс под названием Portia, который может принимать визуальные точки и клики ввода. Он также принимает пользовательские селекторы XPath и CSS Selectors.
Инструменты SEO для Excel
Многие специалисты, с которыми я говорил, признают, что не слышали о SEO Tools for Excel. Тем не менее, по-моему, последняя версия на довольно функциональна и с ней стоит ознакомиться поближе. XpathOnURL() функция может извлекать данные из 10000-х URL. Многопоточные функции плагина также позволяют продолжить работу в Excel на другой вкладке, такова разница между старыми и более новыми версиями!
Screaming Frog
Как я продемонстрировал выше, пользовательская функция извлечения в Screaming Frog является невероятно мощной. Этот инструмент не нуждается ни в каком значении. Все, что я скажу, это то, что он, как правило, мой первый порт-вызов, когда я создаю прототипы новых идей, где необходим XPath.
Обычный пользовательский экстрактор для меня может выглядеть так:



Оставьте ваши контактные данные.
Будем рады обсудить ваш проект!