
Если вы хоть немного интересовались вопросом внутренней оптимизации сайтов, то наверняка встречали термин robots txt. Как раз ему и посвящена наша сегодняшняя тема.
Сейчас вы узнаете, что такое robots txt, как он создается, каким образом веб-мастер задает в нем нужные правила, как обрабатывается файл robots.txt поисковыми роботами и почему отсутствие этого файла в корне веб-ресурса — одна из самых серьезных ошибок внутренней оптимизации сайта. Будет интересно!

Что такое robots.txt
Технически robots txt — это обыкновенный текстовый документ, который лежит в корне веб-сайта и информирует поисковых роботов о том, какие страницы и файлы они должны сканировать и индексировать, а для каких наложен запрет. Но это самое примитивное описание. На самом деле c robots txt все немного сложнее.
Файл robots txt — это как «администратор гостиницы». Вы приходите в нее, администратор выдает вам ключи от номера, а также говорит, где ресторан, SPA, зона отдыха, кабинет управляющего и прочее. А вот в другие номера и помещения для персонала вход вам заказан. Точно так же и с robots txt. Только вместо администратора — файл, вместо клиента — поисковые роботы, а вместо помещений — отдельные веб-страницы и файлы. Сравнение грубое, но зато доступное и понятное.
Для чего нужен файл robots.txt
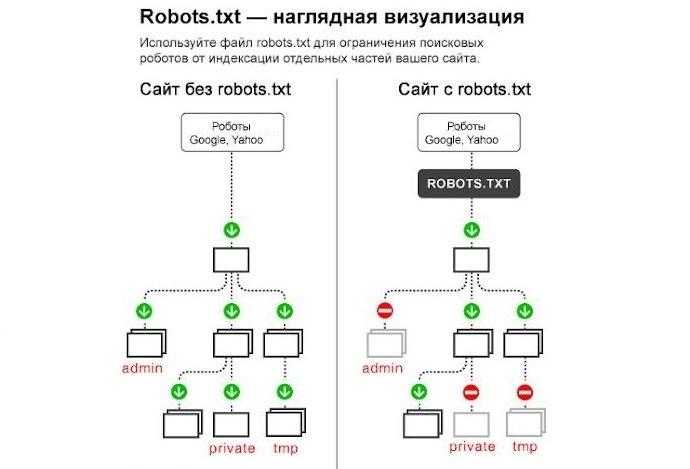
Без этого файла поисковики будут хаотично блуждать по сайту, сканировать и индексировать буквально все подряд: дубли, служебные документы, страницы с текстами «заглушками» (Lorem Ipsum) и тому подобное.
Правильный robots txt не дает такому происходить и буквально ведет роботов по сайту, подсказывая, что разрешено индексировать, а что необходимо упустить.
Существуют специальные директивы robots txt для данных задач:
- Allow — допускает индексацию.
- Disallow — запрещает индексацию.
Кроме того, можно сразу прописать, каким конкретно роботам разрешено или запрещено индексировать заданные страницы. Например, чтобы запретить индексацию директории /private/ поисковым роботам «Гугл», в роботс необходимо прописать User-agent:
User-agent: Google
Disallow: /private/
Также вы можете указать основное зеркало веб-сайта, задать путь к Sitemap, обозначить дополнительные правила обхода через директивы и прочее. Возможности robots txt достаточно обширны.
И вот мы разобрались, для чего нужен robots txt. Дальше сложнее — создание файла, его наполнение и размещение на сайте.
Как создать файл robots.txt для сайта?
Итак, как создать файл robots txt?
Создать и изменять файл проще всего в приложении «Блокнот» или другом текстовом редакторе, поддерживающим формат .txt. Специальное ПО для работы с robots txt не понадобится.
Создайте обычный текстовый документ с расширением .txt и поместите его в корень веб-ресурса. Для размещения подойдет любой FTP-клиент. После размещения обязательно стоит проверить robots txt — находится ли файл по нужному адресу. Для этого в поисковой строке браузера нужно прописать адрес:
имя_сайта/robots.txt
Если все сделано правильно, вы увидите во вкладке данные из robots txt. Но без команд и правил он, естественно, работать не будет. Поэтому переходим к более сложному — наполнению.
Символы в robots.txt
Помимо упомянутых выше функций Allow/Disallow, в robots txt прописываются спецсимволы:
- «/» — указывает, что мы закрываем файл или страницу от обнаружения роботами «Гугл» и т. д.;
- «*» — прописывается после каждого правила и обозначает последовательность символов;

- «$» — ограничивает действие «*»;

- «#» — позволяет закомментировать любой текст, который веб-мастер оставляет себе или другим специалистам (своего рода заметка, напоминание, инструкция). Поисковики не считывают закомментированный текст.
Синтаксис в robots.txt
Описанные в файле robots.txt правила — это его синтаксис и разного рода директивы. Их достаточно много, мы рассмотрим наиболее значимые — те, которые вы, скорее всего, будете использовать.
User-agent
Это директива, указывающая, для каких search-роботов будут действовать следующие правила. Прописывается следующим образом:
User-agent: * имя поискового робота
Примеры роботов: Googlebot и другие.
Allow
Это разрешающая индексацию директива для robots txt. Допустим, вы прописываете следующие правила:
User-agent: * имя поискового робота
Allow: /site
Disallow: /
Так в robots txt вы запрещаете роботу анализировать и индексировать весь веб-ресурс, но запрет не касается папки site.
Disallow
Это противоположная директива, которая закрывает от индексации только прописанные страницы или файлы. Чтобы запретить индексировать определенную папку, нужно прописать:
Disallow: /folder/
Также можно запретить сканировать и индексировать все файлы выбранного расширения. Например:
Disallow: /*.css$
Sitemap
Данная директива robots txt направляет поисковых роботов к описанию структуры вашего ресурса. Это важно для SEO. Вот пример:
User-agent: *
Disallow: /site/
Allow: /
Sitemap: http://site.com/sitemap1.xml
Sitemap: http://site.com/sitemap2.xml
Crawl-delay
Директива ограничивает частоту анализа сайта и тем самым снижает нагрузку на сервер. Здесь прописывается время в сек. (третья строчка):
User-agent: *
Disallow: /site
Crawl-delay: 4
Clean-param
Запрещает индексацию страниц, сформированных с динамическими параметрами. Суть в том, что поисковые системы воспринимают их как дубли, а это плохо для SEO. О том, как найти дубли страниц на сайте, мы уже рассказывали. Вам нужно прописывать директиву:
Clean-param: p1[&p2&p3&p4&..&pn] [Путь к динамическим страницам]
Примеры Clean-param в robots txt:
Clean-param: kol_from1&price_to2&pcolor /polo.html # только для polo.html
или
Clean-param: kol_from1&price_to2&pcolor / # для всех страниц сайта
Кстати, советуем прочесть нашу статью «Как просто проверить индексацию сайта» — в ней много полезного по этой теме. Плюс есть информативная статья «Сканирование сайта в Screaming Frog». Рекомендуем ознакомиться!
Особенности настройки robots.txt для «Гугла»
На практике синтаксис файла robots.txt для этих систем отличается незначительно. Но есть несколько моментов, которые мы советуем учитывать.
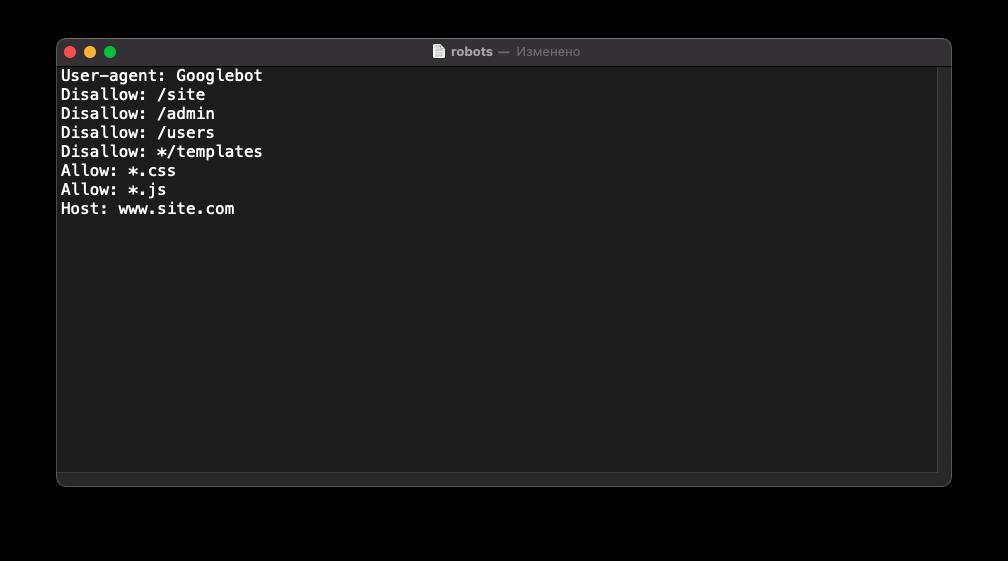
Google не рекомендует скрывать файлы с CSS-стилями и JS-скриптами от сканирования. То есть правило должно выглядеть так:
User-agent: Googlebot
Disallow: /site
Disallow: /admin
Disallow: /users
Disallow: */templates
Allow: *.css
Allow: *.js
Host: www.site.com
Примеры настройки файла robots.txt
Каждая CMS имеет свою специфику настройки robots txt для сканирования и индексации. И лучший способ понять разницу — рассмотреть каждый пример robots txt для разных систем. Так и поступим!
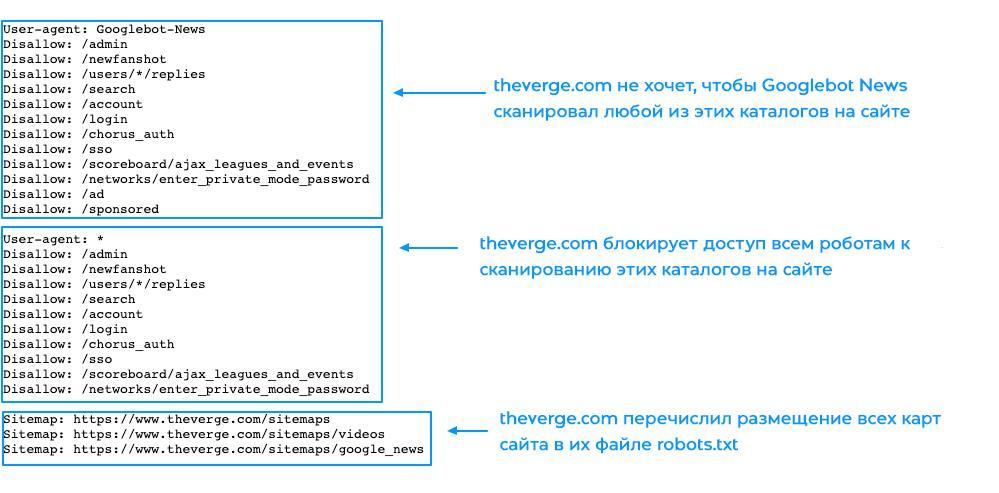
Пример robots txt для WordPress
Роботс для WordPress в классическом варианте выглядит так:
User-agent: Googlebot
Disallow: /cgi-bin # служебная папка для хранения серверных скриптов
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: *?s= # результаты поиска
Disallow: /search # результаты поиска
Disallow: */page/ # страницы пагинации
Disallow: /*print= # страницы для печати
Allow: *.css # открыть все файлы стилей
Allow: *.js # открыть все с js-скриптами
User-agent: *
Disallow: /cgi-bin # служебная папка для хранения серверных скриптов
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: *?s= # результаты поиска
Disallow: /search # результаты поиска
Disallow: */page/ # страницы пагинации
Disallow: /*print= # страницы для печати
Sitemap: http://site.ua/sitemap.xml
Sitemap: http://site.ua/sitemap1.xml
Пример robots.txt для «Битрикс»
Одна из главных проблем «Битрикс» — по дефолту поисковые системы считывают и проводят индексацию служебных страниц и дублей. Но это можно предотвратить, правильно прописав robots txt:
User-Agent: Googlebot
Disallow: /personal/
Disallow: /search/
Disallow: /auth/
Disallow: /bitrix/
Disallow: /login/
Disallow: /*?action=
Disallow: /?mySort=
Disallow: */filter/
Disallow: */clear/
Allow: /bitrix/js/
Allow: /bitrix/templates/
Allow: /bitrix/tools/conversion/ajax_counter.php
Allow: /bitrix/components/main/
Allow: /bitrix/css/
Allow: /bitrix/templates/comfer/img/logo.png
Allow: /personal/cart/
Sitemap: https://site.ua/sitemap.xml
Пример robots.txt для OpenCart
Рассмотрим пример robots txt для платформы электронной коммерции OpenCart:
User-agent: Googlebot
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: /*?page=
Disallow: /*&page=
Disallow: /wishlist
Disallow: /login
Allow: *.css
Allow: *.js
User-agent: *
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: /*?page=
Disallow: /*&page=
Disallow: /wishlist
Disallow: /login
Sitemap: http://site.ua/sitemap.xml
Пример robots.txt для Joomla
В «Джумле» роботс выглядит так:
User-agent: Googlebot
Disallow: /administrator/
Disallow: /cache/
Disallow: /components/
Disallow: /component/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /*?start=*
Disallow: /xmlrpc/
Allow: *.css
Allow: *.js
User-agent: *
Disallow: /administrator/
Disallow: /cache/
Disallow: /components/
Disallow: /component/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /*?start=*
Disallow: /xmlrpc/
Sitemap: http://www.site.ua/sitemap.xml
Пример robots.txt для Drupal
Для Drupal:
User-agent: *
Disallow: /database/
Disallow: /includes/
Disallow: /misc/
Disallow: /modules/
Disallow: /sites/
Disallow: /themes/
Disallow: /scripts/
Disallow: /updates/
Disallow: /profiles/
Disallow: /profile
Disallow: /profile/*
Disallow: /xmlrpc.php
Disallow: /cron.php
Disallow: /update.php
Disallow: /install.php
Disallow: /index.php
Disallow: /admin/
Disallow: /comment/reply/
Disallow: /contact/
Disallow: /logout/
Disallow: /search/
Disallow: /user/register/
Disallow: /user/password/
Disallow: *register*
Disallow: *login*
Disallow: /top-rated-
Disallow: /messages/
Disallow: /book/export/
Disallow: /user2userpoints/
Disallow: /myuserpoints/
Disallow: /tagadelic/
Disallow: /referral/
Disallow: /aggregator/
Disallow: /files/pin/
Disallow: /your-votes
Disallow: /comments/recent
Disallow: /*/edit/
Disallow: /*/delete/
Disallow: /*/export/html/
Disallow: /taxonomy/term/*/0$
Disallow: /*/edit$
Disallow: /*/outline$
Disallow: /*/revisions$
Disallow: /*/contact$
Disallow: /*downloadpipe
Disallow: /node$
Disallow: /node/*/track$
Disallow: /*&
Disallow: /*%
Disallow: /*?page=0
Disallow: /*section
Disallow: /*order
Disallow: /*?sort*
Disallow: /*&sort*
Disallow: /*votesupdown
Disallow: /*calendar
Disallow: /*index.php
Allow: /*?page=
Disallow: /*?
Sitemap: http://путь к вашей карте XML формата
Выводы
Файл robots txt — функциональный инструмент, благодаря которому веб-разработчик дает инструкции поисковым системам, как взаимодействовать с сайтом. Благодаря ему мы обеспечиваем правильную индексацию, защищаем веб-ресурс от попадания под фильтры поисковых систем, снижаем нагрузку на сервер и улучшаем параметры сайта для SEO.
Чтобы правильно прописать инструкции файла robots.txt, крайне важно отчетливо понимать, что вы делаете и зачем вы это делаете. Соответственно, если не уверены, лучше обратитесь за помощью к специалистам. В нашей компании настройка robots txt входит в услугу внутренней оптимизации сайта для поисковых систем.
Кстати, в нашей практике был случай, когда клиент обратился за услугой раскрутки сайта, в корне которого файл robots txt попросту отсутствовал и индексация происходила некорректно. Почитайте, там много интересных моментов: «SEO-Кейс: Продвижение сайта медицинских справок».
FAQ
Что такое файл robots.txt?
Robots txt — это документ, содержащий правила индексации вашего сайта, отдельных его файлов или URL поисковиками. Правила, описанные в файле robots.txt, называются директивами.
Зачем нужен файл robots.txt?
Robots txt помогает закрыть от индексации отдельные файлы, дубли страниц, документы, не несущие никакой пользы для посетителей, а также страницы, содержащие неуникальный контент.
Где находится файл robots.txt?
Он размещается в корневой папке веб-ресурса. Чтобы проверить его наличие, достаточно в URL-адрес вашего веб-ресурса дописать /robots.txt и нажать Enter. Если он на месте, откроется его страница. Так можно просмотреть данный файл на любом сайте, даже на стороннем. Просто добавьте к адресу /robots.txt.



Оставьте ваши контактные данные.
Будем рады обсудить ваш проект!