
В останні роки всіх вражає швидкість, з якою розвивається простір в інтернеті. Регулярно оновлюється дизайн сайтів, додаються нові вкладки на вебресурсах, з'являються нові проєкти. Цей процес настільки запаморочливий, що часом у стрімкому потоці оновлень втрачається важлива інформація. І тоді згадують про один із способів знайти бажане — подивитися, як виглядав сайт раніше, повернутися до попередніх версій. Історія сайту проливає світло на те, як розвивався проєкт, дає уявлення про надійність домену, якщо розглядається питання його купівлі. У цьому матеріалі ми розповімо, що таке вебархіви та як ними користуватися.

Чому важливо знати історію сайту
У цифрову епоху дуже складно вчинити будь-яку дію, при цьому не залишивши цифрового сліду. Це безпосередньо стосується роботи з сайтом. Фіксуються будь-які зміни, внесені до його структури. Зберігається інформація про те, як змінювалася тематика публікацій, який контент розміщувався на окремих сторінках, чи піддавався вебресурс санкціям Google та багато іншого.
Доступ до цих даних особливо корисний для тих, хто:
- займається просуванням вебресурсу;
- хоче створити нову контент-стратегію та прагне зрозуміти, як розвивався проєкт раніше;
- планує купівлю домену;
- шукає дані, видалені з загального доступу, наприклад під час підготовки журналістського розслідування;
- хоче відновити інформацію після кібератаки.
Доступ до попередніх версій дає вебархів сайтів. З його допомогою фахівці різного профілю зможуть дізнатися:
- як сайт виглядав у різні періоди;
- яку тематику мав онлайн-проєкт у різний час;
- яка історія домену і скільки власників змінилося;
- чи попадав вебресурс під штрафні санкції.
Сподіваємося, ми переконали вас у важливості того, що історія вебсайтів має велику цінність. Тож наш наступний крок — навчитися отримувати потрібні дані.
Який принцип роботи вебархівів
Практично відразу після зростання кількості сайтів виникла ідея зберегти їх для історії — так з'явився вебархів. Наприклад, найбільший із них — Internet Archive — був заснований у 1996 році, а збережений контент став доступним з 2001 року. Одним із головних принципів творців є ідея «боротьби зі зникаючими посиланнями».
Власне, вебархів — це найбільша база даних, у якій фіксується стан сайтів на певний час. Тобто спеціальні вебсканери час від часу «відвідують» інтернет-сторінки, створюють їхні копії та зберігають у своєму архіві. Така копія (або «зліпок») прив'язується до конкретної дати. Якщо користувача зацікавила ідея переглянути архів сайту, він може за допомогою спеціальних сервісів побачити, як виглядав ресурс у конкретний день, і простежити, як він змінювався з часом.
Наприклад, популярний сайт Wikipedia, заснований у січні 2001 року, у липні того ж року мав лише 6 000 статей і виглядав так:
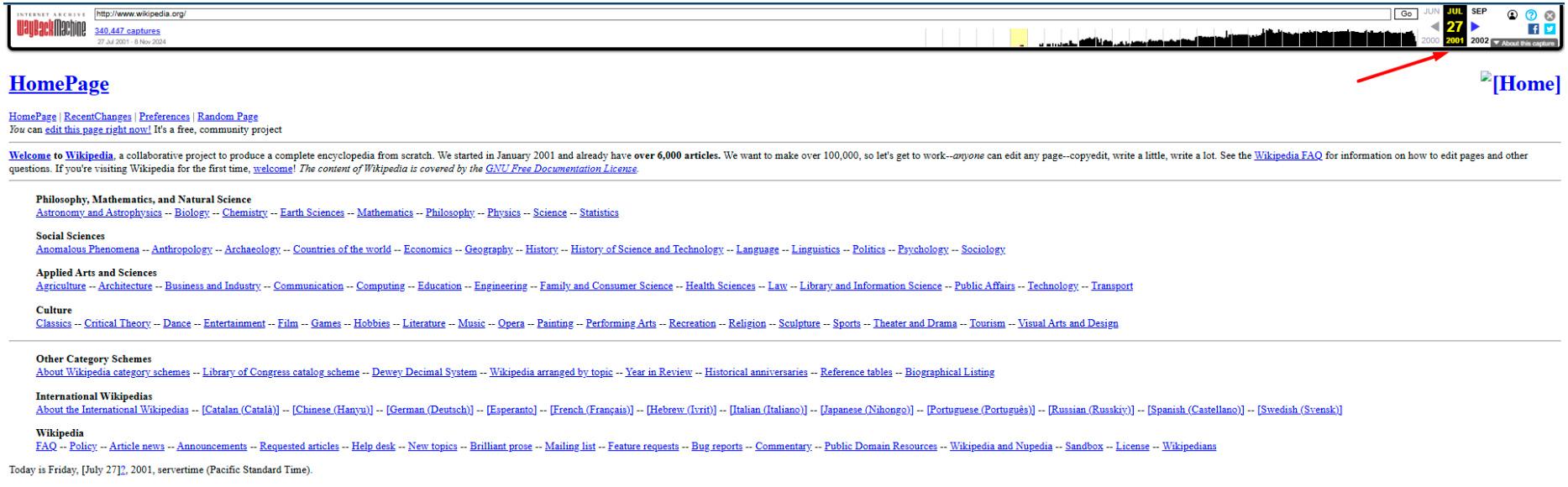
Щоправда, якщо творці обмежать доступ до архівування, копії сторінок можуть не зберегтися.
Сервіси для перевірки історії сайту та їх використання
Знайти архів сайту у відкритому доступі можна за допомогою спеціальних сервісів.
Webarchive
Коли користувача цікавить історія сайту, архів на web.archive.org є найбільш інформативним та зручним інструментом. Недарма його ще назвали Wayback Machine. Цей сервіс справді як справжня «машина часу» для вебресурсу.
Наприклад, ви хочете переглянути стару версію сайту нашої агенції. Для цього введіть нашу адресу в пошуковий рядок і натисніть Enter.
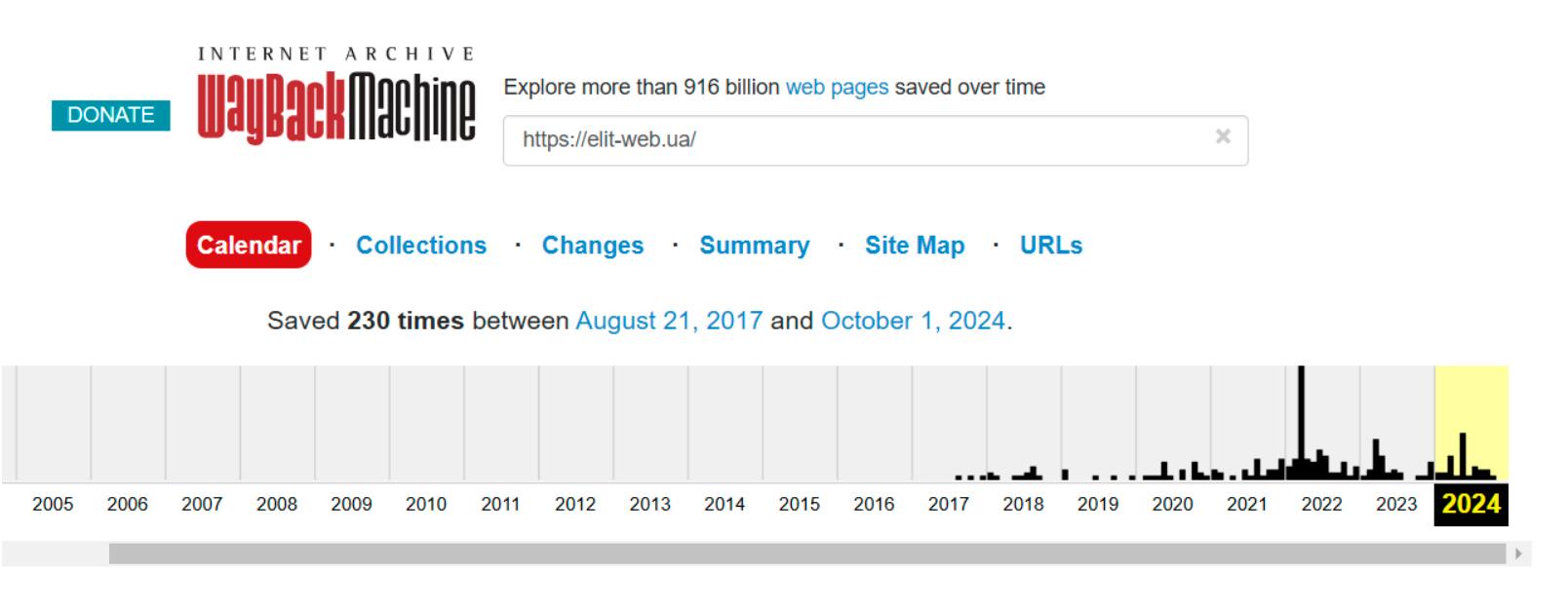
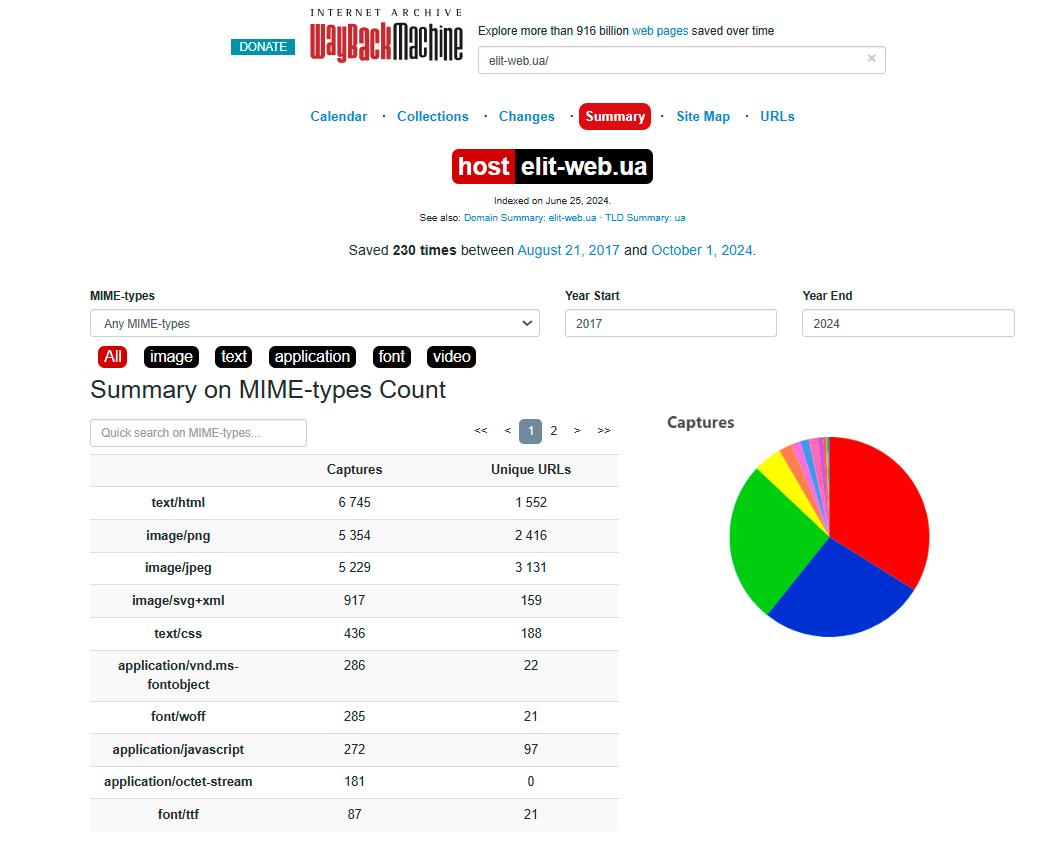
«Стрілка часу», яка відкрилася, покаже, що наш вебресурс був створений у серпні 2017 року і з того часу постійно розвивався. Одне з останніх сканувань матеріалу сайту відбулося 1 жовтня 2024 року.
Якщо вас цікавить конкретна версія сайту, наприклад за 2023 рік, ви можете натиснути на потрібний рік, і відкриється календар, де будуть відзначені дати сканування.
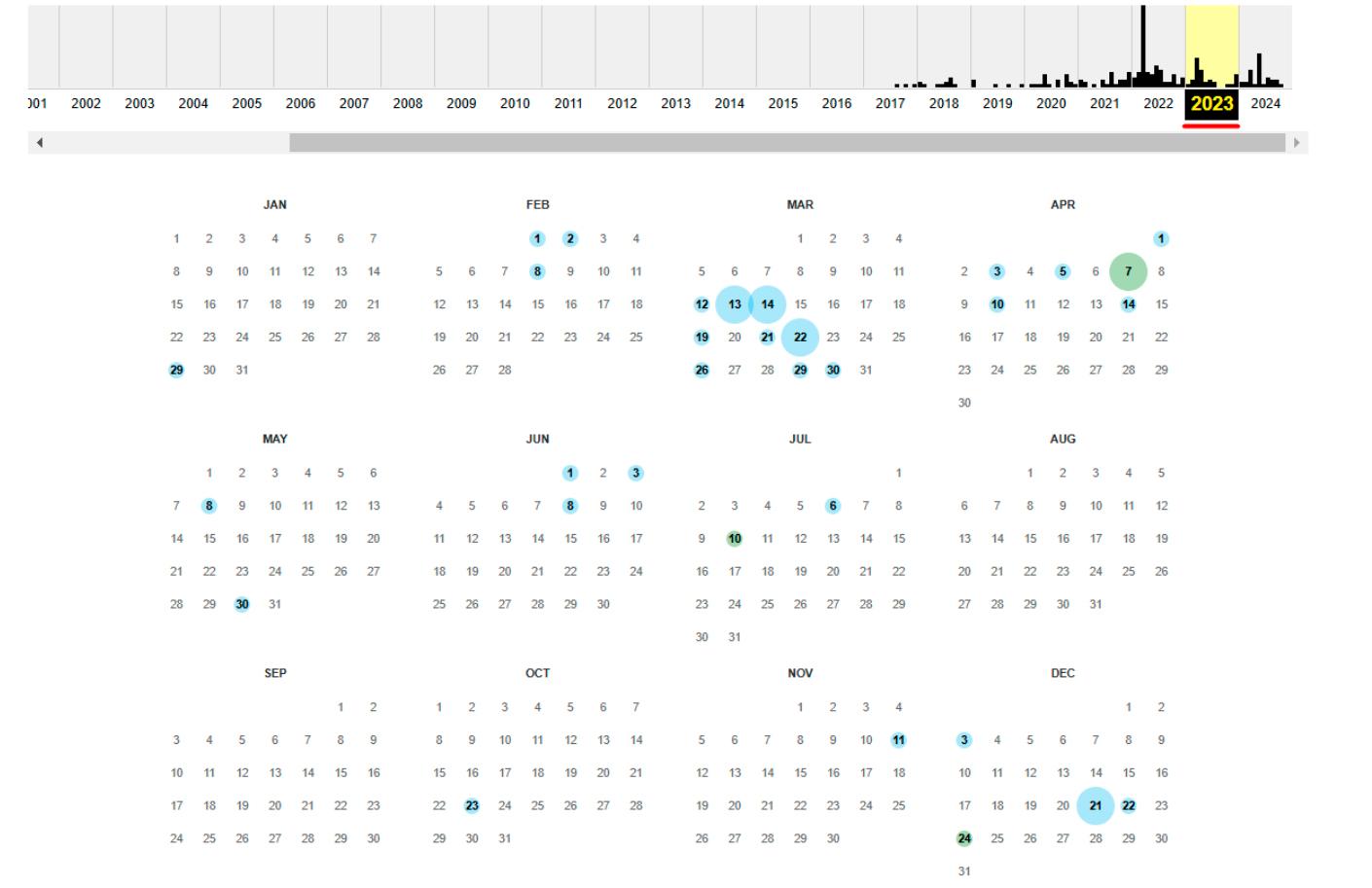
Або якщо ви хочете подивитися, як сайт виглядав у минулому, наприклад, у квітні 2022 року, виберіть цю дату в календарі, і відкриється архівна сторінка.

Після переходу на посилання ви побачите, як виглядав сайт у той час, і зможете переглянути контент, розміщений на сторінках.

На іншій сторінці сервісу відкривається доступ до інформації про зміни на карті сайту.

Про співвідношення типів контенту, представленого на сайті, можна дізнатись через іншу вкладку популярного сервісу.
Whois
Якщо попередній інструмент дає можливість переглянути історію сайту, то Whois більше призначено для перевірки історії доменних імен. З його допомогою ви зможете дізнатися:
- чи вільне доменне ім'я, якщо ви, наприклад, плануєте створити новий проєкт;
- чи піддавався існуючий домен штрафним санкціям;
- коли було зареєстровано домен і коли закінчується період реєстрації;
- де знаходяться сервери, на яких він розміщений.
Сервіс Whois — це свого роду архів доменів. Він дуже простий у використанні: достатньо ввести адресу в пошуковий рядок і відкриється сторінка, на якій буде представлена повна інформація про доменне ім'я.
Чи можна відновити сайт із вебархіву та як це зробити?
Великий плюс сервісу, який зберігає інформацію про все, що було розміщено на сайті раніше, — це можливість знайти потрібну версію вебресурсу та відновити її. Тож фахівці можуть не тільки переглянути історію сайту, а й використовувати знайдені дані у своїй роботі.
Для початку потрібно знайти в вебархіві варіант сайту, що цікавить вас. У цьому допоможе календар, про який ми вже розповіли вище. Якщо потрібні окремі тексти, зображення й інша подібна інформація з попередніх версій, можна завантажити їх у браузері після відкриття потрібної сторінки. Раніше можна було скопіювати повністю стару версію сторінки. Але після масштабного витоку даних восени 2024 року функцію збереження інтернет-сторінок за допомогою їх URL-адрес тимчасово закрито.
Для повного відновлення сайту найкраще використовувати сторонні онлайн-інструменти, наприклад:
- Archivarix;
- Wayback Machine Downloader і деякі інші.
На цих сервісах є функції збереження окремих сторінок або вебресурсу. В останньому випадку на пошту надходить лист із заархівованими даними, після чого сайт можна розмістити на сервері та працювати з ним.
Чи можна знайти унікальний контент у вебархіві?
Розуміючи, що кожен день із мережі зникають десятки ресурсів, цілком логічно припустити, що разом із цим втрачається й цінна інформація. Іноді власники вебресурсів свідомо видаляють дані, що компрометують їх. У той же час інші користувачі можуть захотіти, щоб історія сторінки стала доступною широкому колу. Це, наприклад, на часі, коли проводиться журналістське розслідування.
Якою б не була причина, питання відновлення загубленого контенту залишається актуальним.
Якщо ви шукаєте просто цінний контент на певну тему, найважчий етап — пошук зниклих ресурсів. У цьому вам допоможуть сервіси зі списками доменів, що недавно звільнилися, наприклад ExpiredDomains.net. Далі буде простіше. Ви можете переглядати збережені версії сайтів і шукати потрібний контент.
Журналісту, який бажає перевірити історію сайту та знайти видалені дані, буде простіше: він уже знає, який ресурс йому потрібен. Далі можна просто шукати попередні версії сайту у вебархіві.
Чи можна зробити так, щоб сайт не потрапив до бібліотеки вебархіву?
З урахуванням останніх новин про виток даних із вебархіву, а також з інших причин розробники можуть задуматися про те, що архів вебсторінок — це не така вже й безпечна справа. Якщо у вас виникли подібні побоювання, пропонуємо спосіб, як заборонити створення архівних копій.
Для цього потрібно до файлу robots.txt додати команду, яка забороняє ботам-архіваторам доступ до сайту.

Додатково можна додати noarchive у мікророзмітку заголовка.
Якщо ви бажаєте видалити збережений сайт із Internet Archive, залиште запит про це на сторінці техпідтримки з зазначенням причин такого рішення. Вас повідомлять про ухвалене рішення.
Підсумки
Сподіваємося, що ви розібралися разом із нами, як подивитися сайт у минулому. Пам'ятайте: якщо з вашим сайтом щось станеться, його копії залишаться в архіві, і ви зможете знайти та відновити втрачені дані.




Залишіть ваші контактні дані.
Будемо раді обговорити ваш проект!