

Даже новички в SEO знают, что поисковые роботы Google основывают свою работу на базе данных, в которую включена информация о миллионах страниц. Это индекс результатов поисковой системы. Когда вы выполняете поиск в Google, система просматривает свой индекс и выводит наиболее релевантные результаты. В большинстве случаев владельцы сайтов хотят, чтобы страницы попали в индекс и появлялись в результатах поиска Google. Однако бывают случаи, когда возникает необходимость запретить индексировать сайт. В этой статье мы расскажем, как это сделать.
Почему иногда нужно закрыть сайт или страницу от индексации
Существуют разные причины, чтобы закрыть сайт от поисковиков. К примеру, владельцы порталов или разработчики принимают такое решение, когда:
- нежелательно, чтобы информация просочилась в поисковую систему слишком рано, например когда речь идет о новых услугах или продукте на этапе разработки;
- требуется защитить конфиденциальную информацию. К примеру, в случае если клиент заполняет какие-либо формы на сайте для заказа услуги, важно обеспечить, чтобы персональные данные не стали объектом всеобщего доступа;
- страница, где был ранее размещен контент, фактически удалена, но информация всё еще находится в индексе и может ошибочно отображаться в выдаче;
- были обнаружены дубли контента, к примеру на страницах с фильтрами товаров или дублирующиеся категории, а также неактуальная информация (например, о завершившихся акциях).
От индексации также обычно отключают служебные страницы, которые не имеют ценности для пользователя.
Полезные советы, как закрыть сайт от индексации
Мы предлагаем несколько вариантов, как сделать, чтобы сайт не индексировался.
С помощью Robots.txt
Как известно, доступ поисковых краулеров к страницам и разделам веб-ресурса обеспечивает файл robots.txt. Когда робот сканирует сайт, он следует тем командам или директивам, которые обозначены в этом документе. Эти правила помогают решить, какие страницы сканировать, а какие пропускать. На основании этого принципа вполне логично предположить, что таким образом можно закрыть сайт от индексации, robots txt в этом случае станет тем местом, куда будут внесены изменения.
Чтобы грамотно настроить систему разрешений и запретов для поисковых алгоритмов, полезно понимать, что означают директивы в этом файле:
- user-agent — это своего рода обращение к роботам конкретной поисковой системы либо ко всем роботам;
- disallow — команда, запрещающая индексацию конкретных страниц или разделов сайта;
- allow — директива с противоположным смыслом. Она разрешает индексацию отдельных страниц или разделов;
- sitemap — указатель, демонстрирующий, какие страницы есть на веб-ресурсе и как они связаны между собой. Команда открывает путь к XML-карте сайта.
Чтобы закрыть сайт от индексирования полностью, например на этапе создания проекта, добавьте такую команду:

В этом случае символ «*» после user-agent означает, что правила, описанные в директиве, применяются к роботам из разных поисковых систем. А следующая команда указывает на то, что не нужно индексировать полностью весь сайт.
Если нужно оставить доступ к индексации только для одного поисковика, можно добавить такую команду:

Роботы это прочитают как запрет индексации для всех краулеров, кроме робота Google.
И еще один пример. Если требуется оставить видимой только главную страницу, а все остальные временно скрыть от поисковика, можно добавить такое разрешение:

На эту команду указывают символы «/$» в директиве аllow. Этот метод применяется на этапе разработки сайта. По сути, проект начинает работать, его будут распознавать и оценивать алгоритмы, но доступ к контенту временно остается скрытым.
Используя эти директивы в robots.txt, можно гибко управлять доступом поисковых роботов к сайту в зависимости от этапа его готовности.
С помощью метатега Robots
Обратите внимание: если требуется полностью запретить индексацию сайта, robots txt — это наиболее релевантный метод. Для работы на уровне отдельных страниц лучше в HTML-код страницы добавить метатег:
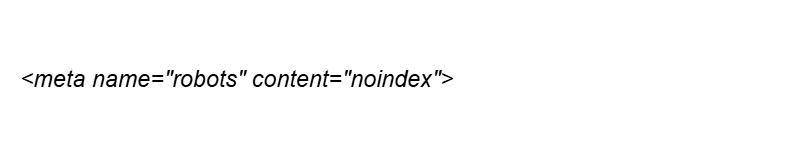
Так вы укажете поисковым роботам не индексировать конкретную страницу.
В этом случае используются четыре основные команды:
- index / noindex — разрешение на индексацию страницы или, соответственно, на запрет этого действия;
- follow / nofollow — разрешение или запрет для бота переходить по ссылкам, размещенным на странице.
В приведенном выше примере указан запрет на индексацию конкретной страницы.

Если вы укажете такие команды, это будет означать, что вы запрещаете не только индексировать содержимое страницы, но и переходить по ссылкам.
Замена robots на, например, bing служит сигналом для запрета добавления в индекс только одной конкретной поисковой системы.
На уровне X-Robots-Tag
Аналогичную команду, помогающую скрыть сайт от поисковиков, можно задать на уровне сервера. Заголовок X-Robots-Tag выполняет эту задачу и позволяет добавлять директивы, которые используются в метатеге robots. Например:

Этот метод полезен для защиты от индексации изображений, PDF-файлов или другого контента, на который нельзя добавить HTML-метатег.
Если вы ведете работы на сервере Apache, добавьте в .htaccess такую команду:

Так вы сможете закрыть сайт от просмотра, индексации и переходов по ссылкам.
На сервере Nginx используйте команду add_header в конфигурационном файле:

С помощью HTTP-кода 403 (Forbidden)
HTTP-код ответа 403 сообщает поисковым роботам, что доступ к странице запрещен. Это непрямой метод, позволяющий закрыть сайт от поисковиков.
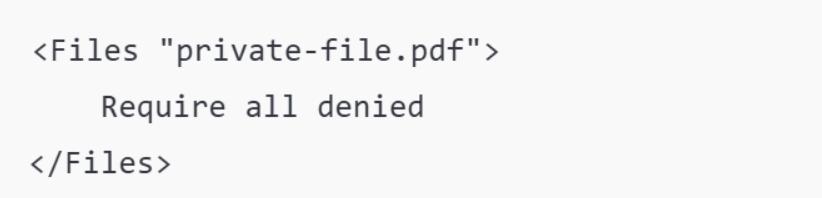
Для выполнения этой процедуры создайте forbidden.html и настройте так, чтобы уведомлять пользователей о закрытом доступе.
Настройте HTTP-код 403 и файл robots.txt. Добавьте команду для отправки HTTP-кода 403 на сервере, например в .htaccess для Apache:
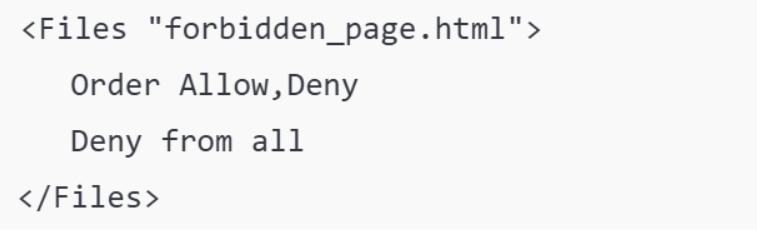
Также добавьте в robots.txt директиву, запрещающую индексацию.
Защита страницы паролем
Парольная защита — еще один способ ограничить доступ к страницам, которые не должны индексироваться. Это полезно не только для того, чтобы отключить индексацию сайта или отдельных разделов, но и для предотвращения доступа пользователей к страницам без знания пароля. Таким способом защищают конфиденциальную информацию.
На серверах Apache можно настроить парольную защиту с помощью .htpasswd и .htaccess. Для этого создайте файл .htpasswd с паролем.
В .htaccess добавьте:

Этот метод удобен для:
- панелей администратора;
- тестовых версий сайта;
- защиты персональной информации от публикации.
В сочетании с директивой disallow в robots.txt это повышает уровень конфиденциальности.
Подводя итоги
Вы узнали, как закрыть сайт от индексации, а теперь остается выбрать метод, который будете использовать. На этапе создания сайта лучше работать с файлом robots.txt. Для ограничения доступа к отдельным страницам подойдет метатег robots или X-Robots-Tag. Если нужно ограничить доступ к важной информации, которая не должна стать всеобщим достоянием, применяйте HTTP-код 403 или защиту паролем. Контролируйте результаты своих действий и при необходимости обращайтесь за помощью к профессионалам.
FAQ
Как отключить сайт от индексации?
Существует несколько методов для этого. Когда необходимо полностью закрыть доступ к веб-ресурсу, используйте файл robots.txt. Добавьте в него команду disallow. Если необходимо отключить от индексирования отдельные страницы, добавьте метатег robots в заголовок страницы.
Зачем закрывать сайт от индексации?
Решение запретить доступ к сайту может быть принято на этапе его разработки, а также во время технических работ или внесении изменений, касающихся юзабилити или общего дизайна веб-ресурса. Доступ к отдельным страницам закрывают, когда обнаруживается дублирование контента или требуется защитить конфиденциальную информацию.
Зачем закрывать ссылки от индексации?
Бывает, что страница, на которую ведет ссылка, фактически уже не существует или удалена, но информация может еще индексироваться поисковиками. В таких случаях необходимо закрыть страницу от индексации и обновить карту сайта, чтобы исправить ошибку. Этот метод также применяется для защиты от дублирования контента или закрытия доступа к неактуальной информации.




Оставьте ваши контактные данные.
Будем рады обсудить ваш проект!